

에어브릿지가 직접 개발한 OLAP DB, Luft에 대해 소개합니다.
Hyojun Kim — 김효준
@therne
에어브릿지는 웹, 앱을 넘나드는 사용자의 유입과 행동을 정확히 파악하여 광고 성과를 측정, 분석하는 제품입니다. 월 2천만대의 디바이스로부터 들어오는 100억 건 이상의 데이터 속에서 사용자들의 행동을 실시간으로 분석한 애널리틱스를 제공하기 위해, AB180에서는 Luft라는 사용자 행동 분석 특화 OLAP 데이터베이스를 자체적으로 개발해 코호트 분석 기능 및 각종 리포트를 제공하는 데 활용하고 있습니다.
코호트 분석 기능? 
코호트 분석은 원하는 유저군 (= 코호트)을 잡아서 해당 유저들의 행동을 분석하는 기법입니다. 예를 들어 "지난 6개월간 우리 앱에서 한달에 10만원 이상 소비한 30대 여성"이란 유저군을 잡은 후, 해당 유저군의 리텐션 (재방문률)을 분석하는 것 등이 코호트 분석에 해당됩니다.
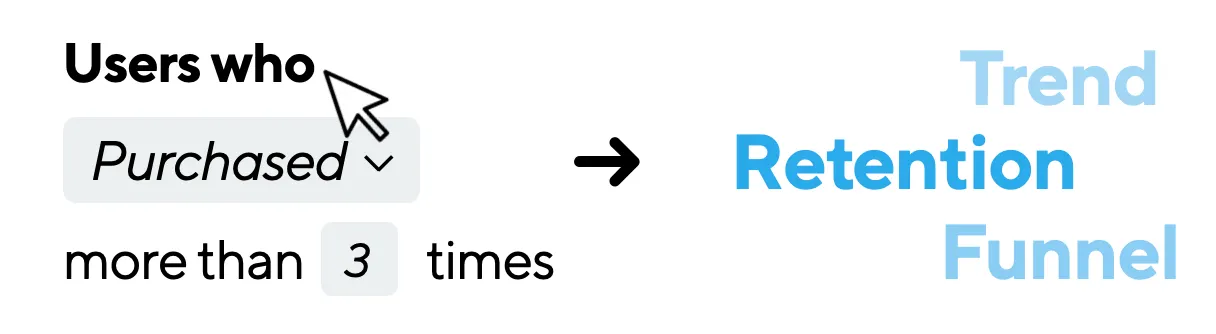
이를 위해선 특정 유저군을 먼저 잡고, 해당 유저들의 이벤트 데이터를 로드해 행동 분석을 수행하는 두 단계를 거쳐야 합니다. 문제는 두 단계의 작업이 모두 시간이 많이 걸리는 데이터 분석이라는 점입니다. 물론 결과를 나중에 이메일로 보낼 수도 있지만, 이럴 경우 데이터 분석가가 조건을 조금씩 바꿔서 결과를 실험해보는게 사실상 불가능해진다는 UX적인 단점이 있습니다. 따라서 저희에겐 대시보드에 즉각 분석 결과가 보여져야 한다는 성능에 대한 니즈가 있었습니다.
기존 아키텍쳐의 한계
한편, Airbridge는 기존에 데이터 분석을 위해 Apache Druid를 사용하고 있었습니다. Druid는 OLAP 데이터스토어로서, 정해진 메트릭을 시간 단위별로 미리 계산해 두는 Pre-Aggregation과 실제 쿼리시에는 필요한 값만 선택해 연산하는 Roll-up 방식을 통해 수 초 내로 통계 쿼리가 가능합니다.
Druid는 저희가 그간 필요했던 다양한 통계 리포트를 제공하는 데에 최적의 솔루션이였지만, 실시간 코호트 분석 기능을 개발하려고 하면서부터 한계를 느끼기 시작했습니다. 저희가 필요한 종류의 쿼리에 비해 한정된 쿼리만을 수행할 수 있다는 점과, 쿼리 성능이 상당히 떨어진다는 (테스트 최소 15-20초) 점이 발목을 잡았습니다.
Pre-Aggregation의 한계: 정해진 종류의 분석만 가능
Druid를 포함한 상당수의 OLAP DB는 정해진 메트릭을 사전에 미리 계산해놓는 Pre-Aggregation을 사용합니다. Raw 데이터를 읽는 게 아니라 이미 계산된 메트릭만 읽기 때문에 빠르게 쿼리를 처리할 수 있습니다. 하지만,
•
사전에 미리 계산해놓지 않은 메트릭은 쿼리할 수 없기 때문에, 새로운 종류의 분석을 수행하려면 데이터를 새로 인덱싱해야 합니다.
•
퍼널 분석 등의 고도화된 행동 분석은 Raw 데이터 없이는 불가능합니다.
따라서 Pre-Aggregation을 사용하는 OLAP DB들은 저희의 니즈를 충족하지 않았습니다.
대부분 솔루션의 성능적 한계 : High-Cardinality Shuffle
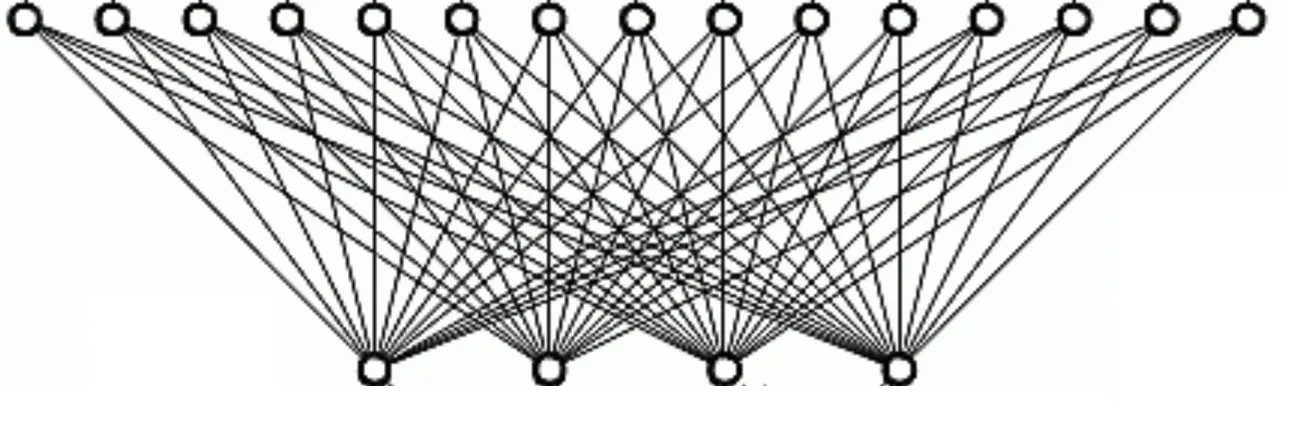
하지만 유저 ID는 매우 높은 Cardinality를 가지는 키기 때문에, Shuffle 과정에서 보틀넥이 크게 발생합니다. 예를 들어 하루에 수백만 이상이 사용하는 고객사가 리포트를 본다면 수백만 유저 ID가 네트워크에서 전송되어야 합니다. 이는 대부분의 솔루션에서 큰 성능 저하의 원인이 됩니다.
자체 개발의 필요성
기존 솔루션을 테스트해보면서 저희의 니즈를 충족하기 위해선 자체 개발해야 한다는 결론에 도착했습니다.
•
비용 효율성 문제: Snowflake나 Redshift 등의 데이터 웨어하우스를 큰 규모로 스케일하면 모든 분석 니즈를 커버하면서 성능도 챙길 수 있습니다. 하지만 상용 데이터 웨어하우스들은 OLAP에 최적화된 것이 아니라 범용적인 니즈를 커버하기 위한 솔루션이기 때문에 목표에 비해서 너무 큰 규모의 클러스터를 운영해야 했습니다.
하지만 유저 행동 분석을 위한 OLAP 쿼리라는 특수성과 데이터의 특성을 고려했을 때 최적화할 수 있는 여지가 무궁무진했기 때문에, 자체 개발로 클러스터 비용을 최대한 줄이고자 했습니다.
•
쿼리의 다양성: 기존에 제공하던 트렌드 및 리텐션 분석 리포트 뿐만 아니라, 퍼널 분석이나 ID 매칭 등의 다양한 니즈를 커버하기 위해서는 SQL 기반 데이터베이스로는 한계가 있었습니다. 지금까지는 Spark 등의 데이터 처리 프레임워크를 통해 이런 분석을 수행했지만, 이러한 솔루션들 역시 성능과 비용 효율성 문제가 있었기 때문에 저희가 자체적으로 커스텀할 수 있는 솔루션이 필요했습니다.

Luft: 유저 행동 분석을 위해 설계한 데이터스토어
Luft는 이런 문제를 해결하기 위해 처음부터 유저 ID 기준 Group By된 유저 행동 분석 쿼리를 빠르게 수행할 수 있도록 설계한 데이터스토어입니다. 현재 저희는 수십 TB 규모의 유저 데이터로부터 코호트 분석을 5대 이하의 노드만으로 평균 3초 ~ 최대 10초 사이에 처리하고 있습니다.
일반적인 RDBMS와는 달리 Luft의 데이터는 불변합니다. 일반적으로 OLAP 데이터스토어는 유저가 일으킨 행동 이벤트 데이터를 분석하는데, 이벤트 데이터는 한번 쌓이면 변하지 않기 때문에 많은 OLAP 데이터스토어들이 한번 데이터스토어에 유입 (Ingestion)된 데이터를 직접 수정될 수 없게 합니다. 대신 필요할 경우 같은 기간의 데이터를 새로 유입해 덮어쓰는 방식으로 보정할 수 있습니다.
불변성을 통해 저희는 DBMS가 필수적으로 해결해야 하는 많은 난제를 간단히 해결할 수 있었습니다. 예를 들어 각종 복잡한 일관성 문제를 해결하느라 클러스터 구조를 복잡하게 만드는 대신 Druid와 같이 심플한 클러스터 디자인을 채택할 수 있고, Kafka처럼 데이터 캐싱 역할을 커널 페이지 캐시에 위임해 복잡한 페이지 매니저 구현 없이도 오히려 더 높은 성능을 낼 수도 있습니다.
하지만 그 중에서도 제일 큰 이점은, 저희가 원하는 형태의 데이터 저장 포맷을 설계할 수 있다는 점이였습니다.
스토리지 엔진
데이터 수정이 필요한 RDBMS에서는 B-Tree나 Skip-List 등의 자료구조를 사용합니다. 하지만 데이터 불변성 덕분에 저희는 자료구조를 유저 행동 분석에 맞게 최적화해 성능을 크게 끌어올릴 수 있었습니다. Luft는 Adroll사에서 만든 TrailDB를 스토리지 엔진으로 채택했습니다.
TrailDB는 유저 이벤트를 저장하기 위해 설계된 로우스토어 (Rowstore)입니다. 데이터는 유저별로 그룹화되고 시간순으로 정렬되어 저장되는데, 유저 이벤트 데이터의 특성을 고려한 다양한 인코딩을 적용합니다.
•
Delta Encoding: 이벤트가 발생 시각 (Event Timestamp)순으로 정렬되기 때문에, 해당 발생 시각 정보는 이전 이벤트 대비 늘어난 만큼만 저장합니다.
•
Dictionary Encoding: 실제 데이터 값을 저장하는 대신, 값을 사전화시켜서 그 ID만 저장합니다.
•
Edge Encoding: 일반적으로 행동 데이터에서 유저에 관한 정보는 변경되지 않기 때문에 (e.g. 나이, 이메일, 디바이스 종류, ...) 이전 이벤트와 달라진 칼럼만 저장해 중복을 제거합니다.
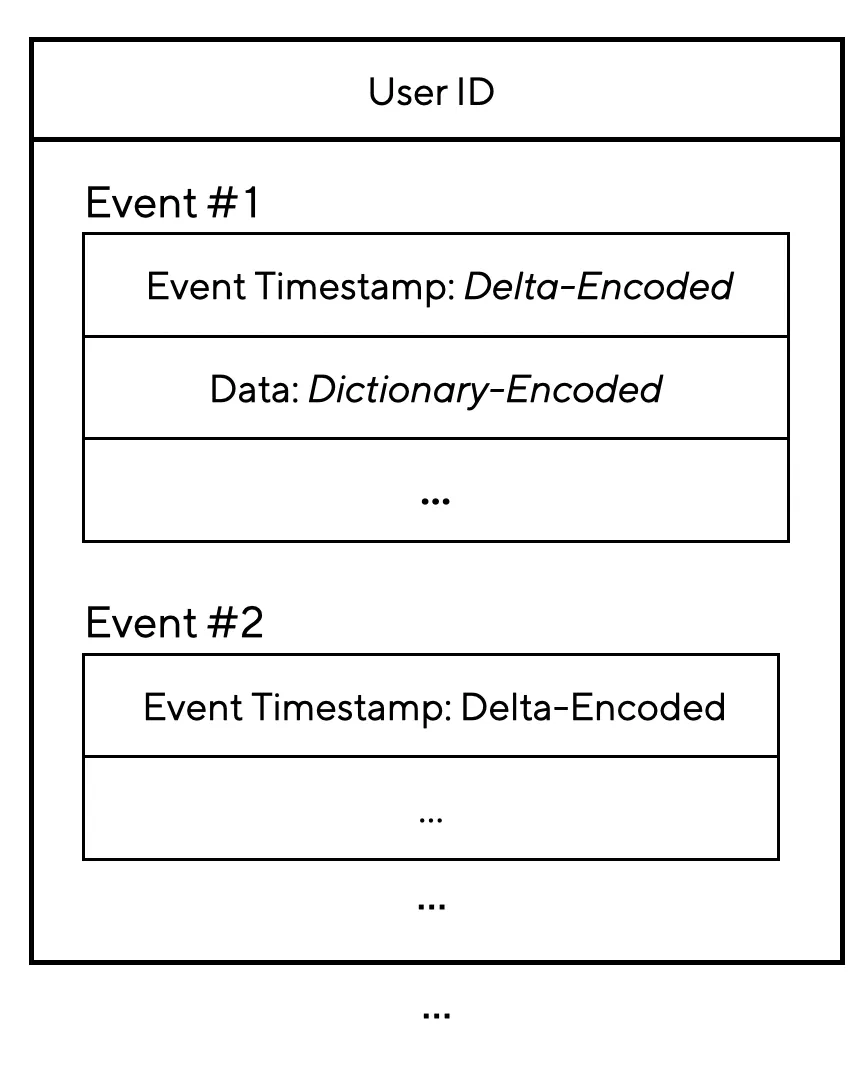
TrailDB의 스토리지 구조 예시: 유저별로 이벤트 데이터가 그룹화됨
이러한 데이터 구조 덕분에 유저 데이터를 TrailDB로 저장하면 디코딩 성능은 O(N)의 시간 복잡도를 그대로 유지한 채 97%의 놀라운 압축률을 기록할 수 있었습니다. 실제로 Airbridge에서 CSV로 추출한 13GB의 샘플 데이터가 TrailDB로 인코딩 시 300mb 수준으로 줄어드는 것을 확인할 수 있었습니다. 데이터 용량이 작다는 건 RAM에 더 많은 데이터를 캐시할 수 있다는 의미죠.
또한 이벤트 데이터가 저장 단계에서부터 이미 유저별로 파티셔닝되어 때문에 Group By 과정에서의 셔플 성능 저하 문제를 해결할 수 있습니다. 그룹화된 유저 데이터를 셔플링하는 게 개별 이벤트를 따로 셔플링하는것보다 부담이 덜하기 때문입니다. 심지어 유저별 데이터의 오프셋이 기록되어 있기 때문에, 원하는 유저의 데이터만을 읽을 수 있어 코호트 분석 시 읽어들일 데이터의 양을 크게 줄일 수 있습니다.
You Only Scan Once
일반적인 사용자 행동 분석 쿼리는 많은 서브쿼리로 이루어져 있습니다. 데이터 스캔 시간을 단축하기 위해, Luft에서는 한번에 필요한 모든 데이터를 스캔하자는 디자인 원칙을 세웠습니다.
에어브릿지의 유저 이벤트는 시계열 데이터이며, 모든 쿼리에도 반드시 기간이 들어갑니다. 따라서 Luft도 이벤트 발생 시각에 따라서 시계열로 데이터를 파티셔닝합니다. 그런데 서브쿼리들 간에 스캔하는 기간이 겹칠 경우 필연적으로 데이터를 중복해서 스캔하는 기간이 생기게 됩니다.
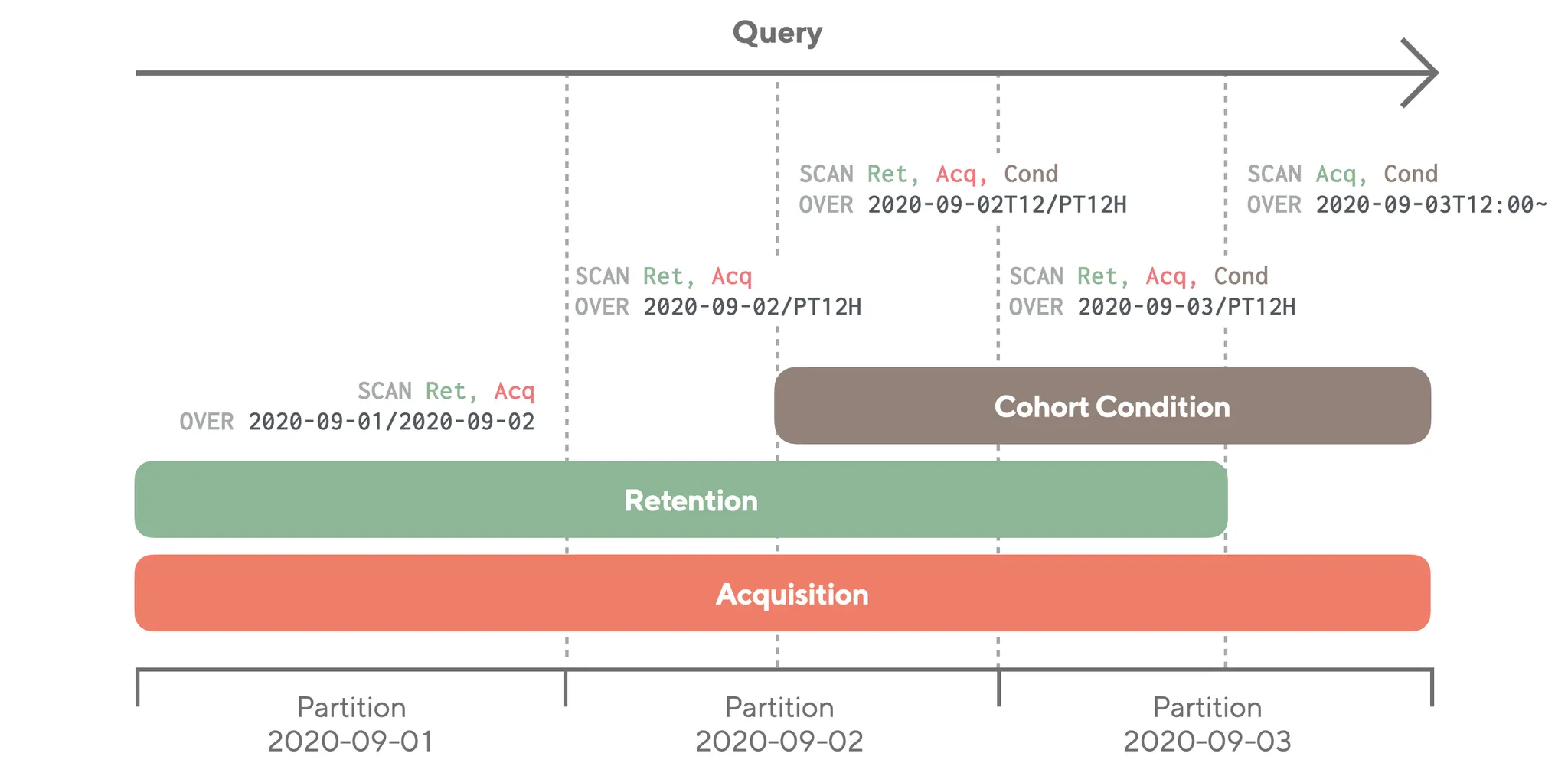
쿼리 최적화 예시: 9월 2일 12시부터 9월 3일까지 특정 행동을 한 사람의 9월 1일부터 9월 3일까지의 리텐션 (재방문)을 분석하는 쿼리를, 시간에 따라 나눠서 같은 서브쿼리끼리 통합해 하나의 쿼리를 만듭니다.
Luft는 쿼리 플래닝 단계에서 한 번의 스캔만 이루어질 수 있게 쿼리를 최적화합니다. 다양한 서브쿼리들을 시간축에 따라 쪼갠 후, 유사한 조건을 가진 쿼리끼리 머지해서 최적화된 서브쿼리를 만들어냅니다. 쿼리 실행 후 결과들은 조인 과정에서 다시 결합되기 때문에, 중복없이 단 한번의 스캔만으로 복잡한 쿼리를 빠르게 수행할 수 있습니다.
Architecture for Consistency
한편 실시간 데이터 쿼리를 위해 기존 솔루션에서 람다 아키텍쳐 (Lambda Architecture)를 차용했습니다. 람다 아키텍쳐는 배치 방식과 스트리밍 방식을 함께 활용하는 데이터 처리 아키텍쳐인데요, 데이터 파이프라인을 실시간인 스피드 레이어와 배치 레이어로 분리하고 실제 서빙 레이어에서 하나로 합쳐서 데이터를 처리합니다. 정합성과 일관성이 떨어지는 실시간 데이터를 나중에 배치 데이터로 덮어쓰기 때문에 결과적 일관성 (Eventual Consistency)을 보장할 수 있다는 장점이 있습니다.
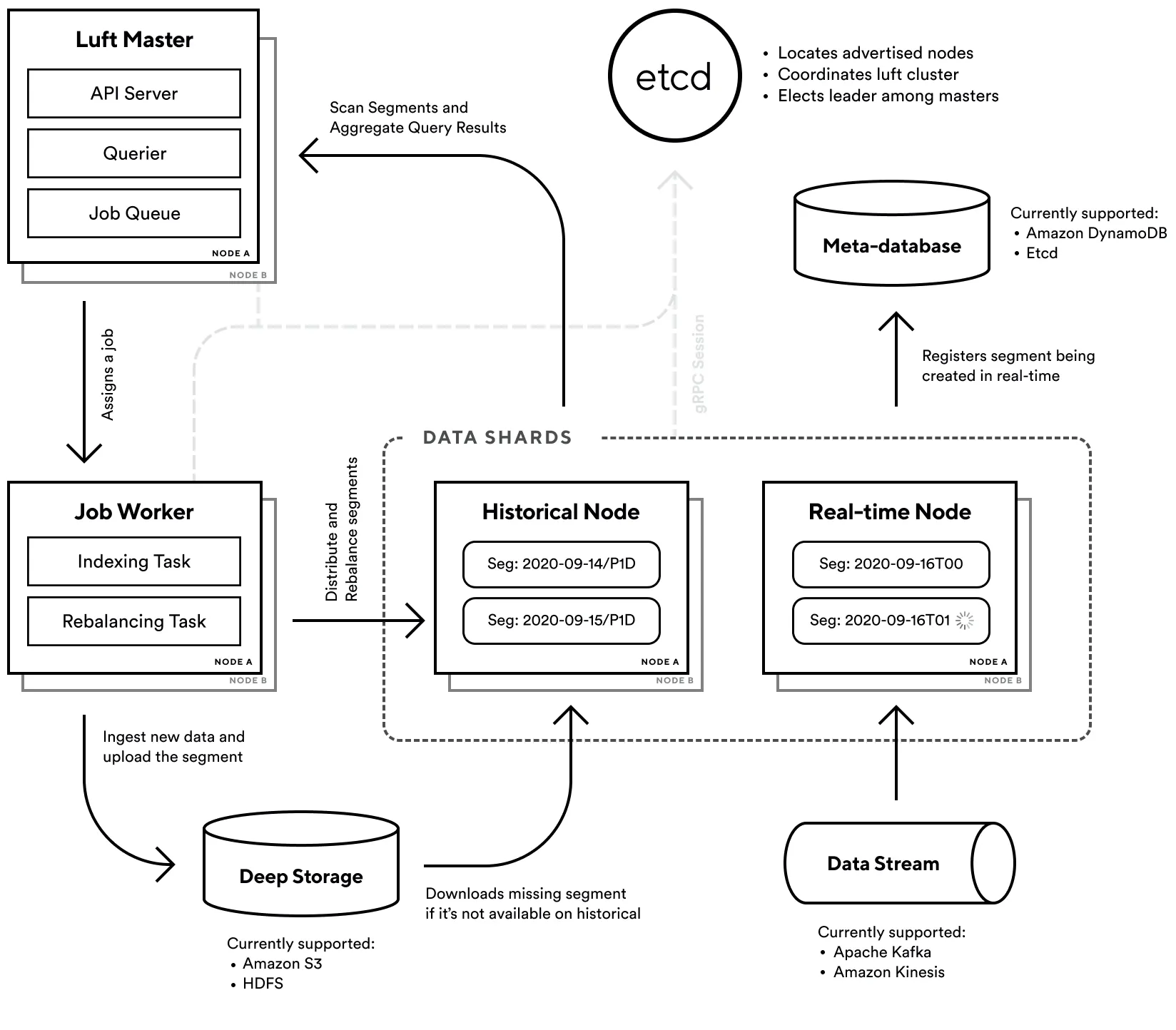
Luft의 클러스터 구조 다이어그램: 배치 데이터를 저장하는 히스토리컬 노드와, Kafka 스트림을 구독중인 리얼타임 노드로부터 마스터 노드가 데이터를 쿼리합니다.
Luft는 람다 아키텍쳐를 사용하고 있는 Druid의 구조를 차용해 노드의 역할을 다음과 같이 나눴습니다.
•
리얼타임 노드: Kafka 등의 데이터 스트림을 구독하며 실시간 데이터를 저장하는 샤드입니다. 실시간으로 들어오는 데이터를 바로바로 저장해 쿼리될 수 있게 합니다.
•
히스토리컬 노드: 배치 데이터를 저장하는 샤드입니다. 배치 데이터를 캐싱하고 쿼리를 수행합니다.
그럼에도 불구하고, 데이터를 여러 노드에 샤딩해 저장하다 보면 장애로 인해서 개별 노드가 가진 데이터가 유실되거나 노드간에 일관성이 맞지 않는 문제가 생길 수 있습니다. 이를 방지하기 위해 데이터는 기본적으로 S3에 저장되고 필요한 데이터만 실제 노드의 디스크 / 메모리에 저장됩니다.
물론 이렇게 하면 만약 쿼리될 데이터가 실제 노드에 없는 경우 S3에서 다운로드하느라 시간이 오래 걸릴 수 있다는 문제가 있지만, 쿼리될 가능성이 높은 최근 데이터 위주로 노드에 저장시키거나 리눅스의 User-Space Page Fault Handler를 이용해 S3에서 데이터를 빠르게 불러오는 방법 등을 통해 Cache Miss에 대비하고 있습니다.
이외에도... 기존 솔루션에서 얻은 인사이트
저희는 Luft를 개발하면서 기존에 만들어진 좋은 솔루션으로부터 많은 인사이트를 얻었습니다.
•
Spark와 Kafka의 디자인을 많이 참고해 Golang과 gRPC로 MapReduce 연산 레이어를 만들었습니다. 파티션 스케줄링 방식과 Pull-based Stream 구조를 통해 높은 성능으로 온라인 쿼리를 처리할 수 있었습니다.
•
etcd로 클러스터를 구성합니다. 일반적으로 ZooKeeper가 많이 사용되지만, ZooKeeper 대비 낮은 운영도와 제약 사항, 그리고 Kubernetes와 같은 프로젝트에서 이미 검증된 바 있다는 점으로 인해 etcd를 채택했습니다.
•
클라우드를 최대한 활용합니다. 데이터를 S3에 저장하고 메타데이터는 DynamoDB에 관리하며, Kubernetes 워크로드의 스케일링을 직접 관리하면서 클러스터 운영 비용을 효과적으로 절감할 수 있었습니다.

저희의 목표는 중소규모 클러스터만으로도 테라바이트 스케일의 유저 행동 분석을 실시간으로 수행할 수 있게 하는 것입니다. 단기적으로는 수십TB 규모의 유저 데이터 위에서 퍼널 분석을 40 CPU Core 미만으로 처리하는 것을 목표하고 있습니다. 이를 위해서 성능을 최적화하고 데이터 구조를 개선하는 데 집중하고 있습니다.
물론 목표를 이뤄나가기 위해선 아직도 풀어나가야 할 많은 문제들이 있지만, 저희는 함께 도전하실 좋은 분들을 모시고 있습니다. 혹시나 관심이 있으시다면, 저희의 데이터베이스 엔지니어 소개 페이지를 살펴봐 주세요!
DEVIEW 2020에서 더 자세히 들으러 가기
더 자세한 내용을 Deview 2020에서 확인하실 수 있습니다. 발표 영상은 아래를 참조해주세요!

ᴡʀɪᴛᴇʀ
Hyojun Kim @therne
Data R&D Engineer
