

Python 애플리케이션을 ARM으로 이전하면서 겪었던 문제들과 해결책을 공유합니다
Frank Yang — 양민석
@puilp0502
목차
1.
에어브릿지 소개
2.
Graviton2 / ARM 소개
3.
그런데 Python은 Cross-platform 언어 아닌가요?
4.
ARM에 맞게 Python 패키지를 빌드하고 배포하기
5.
성과와 한계
AB180 백엔드 팀에서는 비용 절감을 위한 여러 가지 노력을 하고 있습니다. 예를 들어 AWS Spot Instance를 사용해서 컴퓨팅 비용을 줄이거나, Client-Side Rendering을 통해 유저에게 제공하는 페이지를 최적화하거나, 코드 레벨에서의 최적화를 통해 TPS(Transactions Per Second)를 개선하는 작업을 진행해왔습니다.
Preface: Graviton & ARM
Graviton? 그게 뭔데?
먼저 가장 중요한 비용부터 살펴보겠습니다.
동일 vCPU 기준으로, Graviton 인스턴스가 AMD 기반 인스턴스보다 약 11%, Intel 기반 인스턴스보다 20% 가량 저렴한 것을 확인할 수 있습니다.
성능 역시 내부적으로 테스트를 진행했을 때, 동일 vCPU 기준으로 Graviton2 인스턴스가 (저희가 기존에 사용 중이던) AMD 인스턴스와 비슷하거나 더 나은 성능을 보여주는 것을 확인할 수 있었습니다.

AWS는 Graviton2 인스턴스들에 대해서는 1 vCPU당 1 물리 코어를 할당합니다. (x86 계열 인스턴스는 SMT를 사용해 2 vCPU가 1 물리 코어에 할당됨)
따라서, 해당 벤치마크 결과를 Graviton2 코어가 Current-gen x86 코어보다 성능이 좋다고 해석해서는 안 됩니다.
또한 워크로드별로 성능은 천차만별일 수 있기에, 직접 벤치마크 하는 것을 권장합니다!
동일한 성능을 더 저렴한 비용으로 이용할 수 있다면 주의해야 할 점으로는 무엇이 있을까요? Graviton 인스턴스는 AWS EC2 최초로 x86 계열이 아닌 프로세서를 사용합니다. 기존의 인스턴스들은 Intel 또는 AMD의 프로세서를 사용했지만, Graviton Instance들의 경우 AWS가 직접 설계한 ARM ISA 기반 프로세서를 사용합니다.
ARM은 일반적으로 ARM Holdings사에서 설계하는 ISA와 해당 ISA를 사용하는 프로세서를 통칭하는 용어이지만, 여기서는 ARM ISA만을 지칭하는 용어로 사용하였습니다.
몇 가지 용어 정리 후 운영상의 차이점을 알아보겠습니다.
프로세서와 아키텍처, ISA
컴퓨터구조 수업 첫 시간을 다시 떠올려봅시다.
•
ISA (Instruction Set Architecture; 명령어 집합 구조)
기계어(Machine Code)를 해석하고 실행하는 방식에 대한 정의를 ISA라고 합니다. 예를 들어, 컴퓨터가 01 45 fc 라는 기계어를 만났을 때 어떻게 해석할지에 대한 정의가 필요합니다. 해당 기계어에 대해 "메모리에 있는 특정 값과 레지스터에 있는 값을 더하라"고 정의해 주는 것이 바로 ISA입니다.
대표적인 ISA로는 x86, MIPS, ARM, RISC-V 등이 있으며, 이러한 ISA는 각 프로세서 제조사의 홈페이지에서 찾아볼 수 있습니다.
•
Microarchitecture (µarch)
특정 ISA에 맞게 설계한 프로세서의 구조를 마이크로아키텍처라고 부릅니다. 아래는 그 예시들입니다.
◦
Cortex-A78 : ARMv8 ISA를 구현한 마이크로아키텍처입니다. 휴대폰 스펙 시트에서 자주 볼 수 있습니다.
◦
Intel Skylake : x86 ISA를 구현한 마이크로아키텍처입니다.
◦
Neoverse N1 : 마찬가지로 ARMv8 ISA를 구현한 마이크로아키텍처입니다.
위 예시를 통해 동일한 ISA를 대상으로 하는 여러 마이크로아키텍처가 존재할 수 있다는 것을 알 수 있습니다. Neoverse N1 역시 다른 Cortex 계열 µarch와 마찬가지로 ARM ISA를 대상으로 하지만, 서버에서 사용될 목적으로 설계되었다는 점이 가장 큰 차이점입니다.
•
프로세서
마이크로아키텍처를 실리콘 덩어리에 구워내서 실제로 계산을 할 수 있도록 만든 물건을 프로세서라고 부릅니다. 즉, Graviton2 프로세서는 AWS가 Neoverse N1 마이크로아키텍처 기반으로 설계해서 생산한 프로세서입니다.
ISA가 다르다는 것
아래와 같은 C 코드를 가정해 보겠습니다.
#include <stdio.h>
int main() {
int i, sum = 0;
for (i = 1; i <= 10; i++) {
sum += i;
}
printf("%d\n", sum);
return 0;
}
C
복사
해당 명령어를 x86 머신과 ARMv8 머신에서 gcc -g -O0 a.c 명령어를 통해 컴파일한 뒤 비교해보겠습니다.
x86 머신의 컴파일 결과
ARMv8 머신의 컴파일 결과
동일한 소스 코드를 컴파일했음에도 불구하고, 위와 같이 컴파일한 바이너리의 내용이 다른 것을 확인할 수 있습니다. 이렇게 기계어 수준에서 다르기 때문에 x86에서 컴파일한 바이너리는 ARMv8에서 사용할 수 없습니다. 나아가, 일부 라이브러리에서는 x86에서만 사용 가능한 명령어 확장을 사용하는 경우도 있습니다 (e.g. Intel MKL). 이 경우 다른 ISA로 이전 시 성능 감소 또는 호환성 문제를 일으킬 수 있습니다.
하지만 에어브릿지에서는 Python을 주력 언어로 사용하고 있었고, 특정 아키텍처에 최적화된 라이브러리를 사용하고 있지 않았기 때문에 이와 관련된 문제는 없을 것으로 예상했습니다.
위 조사 결과를 가지고 팀 내 논의를 거친 후, 에어브릿지의 컴퓨팅 비용 중 가장 많은 비중을 차지하는 광고 트래킹 서버를 Graviton Instance로 운영할 수 있을지 검증해보기로 했습니다.
Graviton Instance로 운영해도 좋을 것 같다고 판단한 근거는 아래와 같았습니다.
1.
AWS ECS 환경에서 운영하고 있고 Dockerize 되어 있으므로 migration에 큰 비용이 들지 않을 것으로 예상했습니다. 그러나 이것은 잘못된 예상이었습니다.
2.
위 예상이 맞다면, 작업에 들이는 노력으로 얻을 수 있는 10%의 비용 절감 효과가 가치 있다고 판단했습니다.
3.
코어 수에 대한 이점이 있어서 성능 향상도 이루어 낼 수 있으리라 예상했습니다.
Proof-of-Concept: ARM에서 돌아가는 트래킹 서버 빌드하기
Using Python on ARM
Python은 인터프리터 언어입니다. 즉, 프로그램을 실행할 때 바이너리로의 컴파일 과정이 필요 없습니다. 여기까지만 봐선 아무 문제가 없을 것 같지만 Python 패키지는 바이너리를 포함할 수 있다는 점이 문제가 됐습니다.
Python 패키지의 종류
우선 Python 패키지의 종류를 살펴보겠습니다.
<내용물에 따른 구분>
1.
Pure-Python Package
•
순수 Python 코드로만 이루어진 패키지
•
Django, Flask 등이 해당
2.
Python Package with Extension Module
•
Python 확장 모듈을 포함하는 패키지
•
Numpy 등이 해당
<패키징 형태에 따른 구분>
1.
Source Distribution
•
이름 그대로 패키지 소스 코드만 담고 있는 패키지 (일반적으로 .tar.gz 형태)
•
설치하려면 일련의 빌드 과정이 필요
2.
Built Distribution
•
미리-빌드된 패키지
•
추가적인 빌드 과정 없이 바로 설치 가능
•
일반적으로 Wheel 형태 (.whl)
Python 패키지에 빌드 과정이 왜 필요한가요?
많은 Python 패키지는 Python 확장 모듈 (Extension Module)을 포함합니다. 확장 모듈이란, 쉽게 말해서 C/C++로 작성된 Python 모듈입니다. C/C++같은 저수준 언어를 사용하는 이유는 여러 가지가 있으나, 주로 속도 향상 또는 기존에 존재하던 라이브러리의 바인딩 제작을 위해 사용됩니다.
Python으로 Scientific Computing을 할 때 필수적으로 사용되는 Numpy / Scipy도 이러한 확장 모듈에 해당합니다 (정확히는 Cython을 통해 C 코드를 생성 후 컴파일). 이러한 모듈들을 사용하기 위해선 C/C++ 소스 코드를 빌드하는 과정이 필요합니다.
하지만 pip install 을 할 때마다 빌드하는 과정을 거칠 경우 아래와 같은 문제들이 있습니다.
•
패키지 설치가 느려집니다.
•
패키지 설치 시 C/C++ 소스 코드의 의존성(컴파일 타임 의존성)이 필요합니다.
Python 환경에서 개발 환경 설치를 할 때 자주 겪는 mysqlclient 오류도 확장 모듈 소스 코드의 의존성 문제로 인해 발생하는 오류입니다.
그래서 나온 것이 바로 Built Distribution입니다. Built Distribution은 내부에 미리 소스 코드를 빌드한 바이너리를 포함해서, 설치자 시스템— pip install 을 실행하는 시스템—에서 추가적인 빌드 과정 없이도 패키지가 설치될 수 있게 합니다. 하지만 위에서 설명한 것처럼, C/C++ 코드를 컴파일해서 나오는 바이너리 형태는 플랫폼 별로 달라집니다. 그렇기 때문에 Built Distribution (.whl) 파일은 타깃 플랫폼별로 존재해야 합니다.
만약 패키지 작성자가 설치자 시스템과 호환되는 Wheel을 PyPI에 올려두지 않았다면, Source Distribution을 통해 패키지를 직접 빌드해서 사용할 수밖에 없습니다.
Python 패키지 설치 과정 3줄 요약
1.
내 플랫폼에 맞는 Wheel이 빌드되어서 PyPI에 올라와 있을 경우
⇒ Wheel을 통한 설치 (컴파일러 툴체인, 컴파일타임 의존성 설치 필요 X)
2.
내 플랫폼에 맞는 Wheel이 없지만 sdist는 존재할 경우
⇒ sdist를 받아 빌드해서 설치
a.
Pure-Python 패키지일 경우 ⇒ 추가적인 요구사항 X
b.
Extension Module을 포함하는 패키지일 경우 ⇒ 확장 모듈 빌드 후 설치 (컴파일러 툴체인, 컴파일 타임 의존성이 이미 설치되어 있어야 함)
3.
내 플랫폼에 맞는 Wheel이 없고 sdist도 존재하지 않는 경우
⇒ 설치 불가능
2, 3번에 해당하는 패키지를 잘 설치하는 것이 Python 애플리케이션을 ARM으로 이전하는데 있어 가장 어려운 부분이라 할 수 있습니다.
확장 모듈이 포함된 Python 패키지 ARM에서 설치하기: 실전 편
이제 실제로 광고 트래킹 서버를 ARM으로 이식하면서 설치에 문제가 있었던 패키지들을 어떻게 해결했는지 살펴보겠습니다.
confluent-kafka-python 패키지는 Confluent사에서 제공하는 Python용 고성능 Kafka 클라이언트 라이브러리입니다. 안타깝게도 해당 라이브러리는 ARMv8용 Built Distribution이 존재하지 않기 때문에, Source Distribution을 받아와서 확장 모듈을 빌드하는 과정이 필요합니다. 게다가 확장 모듈이 librdkafka 라는 외부 의존성을 가지고 있었기 때문에 해당 외부 의존성을 설치하는 과정도 필요했습니다.
#17 25.29 gcc -pthread -Wno-unused-result -Wsign-compare -DNDEBUG -g -fwrapv -O3 -Wall -fPIC -I/usr/local/include/python3.8 -c confluent_kafka/src/confluent_kafka.c -o build/temp.linux-aarch64-3.8/confluent_kafka/src/confluent_kafka.o
#17 25.29 In file included from confluent_kafka/src/confluent_kafka.c:17:
#17 25.29 confluent_kafka/src/confluent_kafka.h:55:2: error: #error "confluent-kafka-python requires librdkafka v1.0.0 or later. Install the latest version of librdkafka from the Confluent repositories, see http://docs.confluent.io/current/installation.html"
#17 25.29 #error "confluent-kafka-python requires librdkafka v1.0.0 or later. Install the latest version of librdkafka from the Confluent repositories, see http://docs.confluent.io/current/installation.html"
#17 25.29 ^~~~~
#17 25.29 confluent_kafka/src/confluent_kafka.c: In function ‘error_cb’:
#17 25.29 confluent_kafka/src/confluent_kafka.c:1226:20: error: ‘RD_KAFKA_RESP_ERR__FATAL’ undeclared (first use in this function); did you mean ‘RD_KAFKA_RESP_ERR__FAIL’?
#17 25.29 if (err == RD_KAFKA_RESP_ERR__FATAL) {
#17 25.29 ^~~~~~~~~~~~~~~~~~~~~~~~
#17 25.29 RD_KAFKA_RESP_ERR__FAIL
#17 25.29 confluent_kafka/src/confluent_kafka.c:1226:20: note: each undeclared identifier is reported only once for each function it appears in
#17 25.29 confluent_kafka/src/confluent_kafka.c:1228:23: warning: implicit declaration of function ‘rd_kafka_fatal_error’; did you mean ‘rd_kafka_last_error’? [-Wimplicit-function-declaration]
#17 25.29 err = rd_kafka_fatal_error(rk, errstr, sizeof(errstr));
#17 25.29 ^~~~~~~~~~~~~~~~~~~~
#17 25.29 rd_kafka_last_error
#17 25.29 error: command 'gcc' failed with exit status 1
#17 25.29 ----------------------------------------
Plain Text
복사
librdkafka 외부 의존성 부재로 인해 confluent-kafka-python 패키지 설치에 실패하는 모습.
가장 처음 시도한 것은 Docker 이미지 빌드 과정에서 librdkafka 패키지를 설치한 후, confluent-kafka-python 패키지를 설치하는 것이었습니다. 하지만, 기존에 사용하던 Debian 기반 Python 이미지에서 패키지 매니저로 설치할 수 있는 librdkafka 의 버전이 너무 낮아서 빌드에 실패했습니다.
이후 해당 패키지 설치를 위해 고려해 본 방안들은 다음과 같습니다:
1.
Dockerfile 내에서 librdkafka 소스 컴파일 후 설치
빌드는 정상적으로 됐습니다. 하지만 이미지 빌드 시마다 매번 confluent-kafka-python 빌드 뿐만 아니라 툴체인 설치 및 librdkafka 빌드가 필요하기 때문에 총 빌드 시간이 너무 오래 걸려서 좋지 않은 방법이라 판단했습니다.
2.
Alpine 기반 Python 이미지 사용
Alpine 기반 Python 이미지에서는 librdkafka의 원하는 버전이 패키지 매니저에서 제공되었기에, 해당 이미지를 기반으로 빌드를 시도했습니다. 실제로 해보니 confluent-kafka-python은 정상적으로 설치할 수 있었지만, 다른 라이브러리가 Alpine 이미지에 설치되어있지 않은 라이브러리를 요구하여 또 다른 부작용이 생겼습니다.
궁극적으로, Base Image를 바꾸는 건 너무 위험하다고 판단하여 이 방법도 유보하였습니다.
3.
커스텀 Python 이미지 사용
confluent-kafka-python 패키지가 요구하는 librdkafka 라이브러리 버전이 Debian에는 존재하지 않았지만 Ubuntu 20.04에는 존재했기 때문에 20.04 기반의 Python Base Image를 만들어서 사용하는 방법을 고려했습니다.
실제로 PoC 진행 시에는 이 방법으로 진행하였으나, 추후 다른 문제점이 발견되어 (Zstd 지원 누락) 해당 방법 또한 사용할 수 없었습니다.
위와 같은 시행착오들 끝에 프로덕션에서는 아래와 같은 방법을 사용하기로 결정하였습니다.
•
confluent-kafka-python 패키지의 ARMv8용 Built Distribution (Wheel)을 만드는 과정을 자동화 (빌드 파이프라인 구성)
•
해당 Wheel을 사설 Python Index에 업로드
•
Docker 이미지 빌드 시에는 사설 인덱스로부터 이미 만들어진 wheel을 가져와 패키지 설치
minify-html 패키지는 사용자에게 제공되는 HTML 데이터의 크기를 최적화하기 위해 사용하던 패키지입니다. 해당 패키지는 다른 일반적인 패키지들과는 달리 Source Distribution도 제공하지 않습니다(!). 즉, 설치자 시스템에 맞는 Wheel이 없을 경우, 바로 설치에 실패합니다.
PoC 진행 중에는 실제 ARM 머신에서 Go와 Rust 툴체인을 설치한 후 해당 패키지의 빌드 과정을 따라가면서 Wheel을 생성한 다음 사용하였습니다.
해당 패키지의 빌드 시스템을 살펴보면 다음과 같습니다.
•
코어 로직은 Rust+Go로 작성되어 있습니다.
•
HTML Minify 로직은 해당 패키지 내부에 Rust로 작성되어 있고, JS Minify는 Go로 작성된 esbuild의 Rust 바인딩인 esbuild-rs를 사용합니다.
•
일부 빌드 관련 스크립트는 Typescript 코드로 작성되어 있습니다.
•
Maturin 툴킷을 사용해 Rust 코드를 Python 패키지로 빌드합니다.
.svg&blockId=e3cfa592-102e-40a2-a948-11e69285ac7e)
즉, 해당 패키지를 빌드하기 위해선 Node + Rust + Go 툴체인이 빌드 시스템에 설치되어 있어야 합니다. 이렇게 복잡한 빌드 시스템을 요구하는 패키지는 제거하는 것이 차라리 운영상 이점이 더 크다고 판단하여 실제 프로덕션 배포 시에는 해당 의존성을 제거하였습니다.
Going Production: 실제로 적용하기
PoC를 통해 트래킹 서버가 ARM에서 돌아갈 수 있다는 것을 확인한 후, 프로덕션에서 사용할 수 있도록 기존 인프라 수정 및 신규 인프라 구축 작업 또한 진행하였습니다.
Packaging
광고 트래킹 서버는 AWS ECS 위에서 서비스되고 있고, 따라서 Dockerized 된 상태의 빌드 결과물이 필요합니다. 로컬 개발환경은 x86이기 때문에, 로컬과 프로덕션의 결과물을 분리하지 않기 위해서 docker의 buildx 기능을 이용해서 Multi-arch 이미지를 만드는 것을 목표로 했습니다.
그러나, 실제로 x86 빌드 시스템에서 Multi-arch 이미지를 만들어보니 빌드 타임이 너무 길어졌고, 환경별로 빌드 결과물이 따로 나오더라도 시간을 단축하는 것이 중요하다고 판단해 단일 플랫폼 이미지를 사용하기로 결정했습니다.
이에 따라, 이미지 태그 변경 및 ECS Task Definition 수정 작업 또한 진행했습니다.
Custom Dependency Management
ARMv8을 지원하지 않는 라이브러리들을 사용하기 위해 의존성 빌드 및 배포를 위한 파이프라인 또한 구축하였습니다.
•
Docker를 이용해 confluent-kafka-python wheel을 만들고, 이를 사설 Python 패키지 인덱스에 배포하는 파이프라인을 구축했습니다.
•
s3pypi 라는 라이브러리를 이용해 S3를 패키지 인덱스로 사용했습니다.
◦
디렉터리 리스팅이 지원되는 웹사이트는 Python 패키지 인덱스로 사용할 수 있습니다. 즉, 패키지 추가 시마다 리스트만 생성해 주면 S3도 패키지 인덱스로 사용할 수 있습니다.
.
├── bar
│ └── bar-0.1.tar.gz
└── foo
├── Foo-1.0.tar.gz
└── Foo-2.0.tar.gz
C
복사
•
사설 인덱스에서 x86, arm64 패키지를 모두 제공하게 했습니다.
◦
처음에는 x86 계열에서는 pypi.org를 사용하고 arm64 계열에서만 사설 인덱스를 사용하게 하려고 했습니다. 하지만 Poetry(Python 의존성 관리자)에서 해당 기능을 지원하지 않았기 때문에 어쩔 수 없이 계획을 변경했습니다.
◦
항상 자체 인덱스를 사용하도록 설정하는 대신, 패키지 배포 파이프라인에서 공식 저장소의 바이너리를 사설 인덱스에 자동으로 업로드하는 스크립트를 추가하는 방식으로 두 플랫폼에 대한 지원을 추가했습니다.
◦
Poetry에서 사설 인덱스를 추가하는 방법은 다음과 같습니다.
--- a/pyproject.toml
+++ b/pyproject.toml
+[[tool.poetry.source]]
+name = "airrepo"
+url = "http://repository.example.com/"
+# 패키지가 PyPI에 없을때만 해당 인덱스를 찾아보려면:
+# secondary = true
+
C
복사
Continuous Integration Migration
Multi-arch 이미지를 만들지 않기로 결정했기 때문에 기존에 사용하던 x86 기반의 CI를 ARMv8 기반으로 변경하는 것이 필요했습니다. 저희는 CI 시스템으로 AWS CodeBuild를 사용하고 있었고, CodeBuild에서 사용하는 Image로는 AWS가 제공하는 aws-codebuild-docker-images에 빌드 시스템 디펜던시를 추가한 이미지를 만들어 사용하고 있었습니다. 해당 Repo에는 AWS가 기본으로 제공하는 aarch64 이미지의 Dockerfile도 존재하므로 이 파일에 빌드 시스템 디펜던시들을 추가하여 ARM 기반 Image를 생성했습니다.
다음으로 생성한 CodeBuild Image를 CodeBuild Project에 적용했습니다. 저희는 CodeBuild를 비롯한 대부분의 AWS Infra를 terraform으로 관리하고 있습니다. Terraform에서도 쉽게 사용할 수 있도록 CodeBuild module에 environment_test_type = "ARM_CONTAINER" 옵션을 주어서 ARM 기반의 Container를 사용하도록 했습니다.
마치며
결과와 한계
에어브릿지에서 Graviton2 인스턴스 타입을 도입한 결과는 다음과 같습니다.
장점
•
비용 감소
◦
Graviton2 도입 이후, 단위비용 당 리퀘스트 처리량이 10% 가량 증가한 것을 확인할 수 있었습니다.
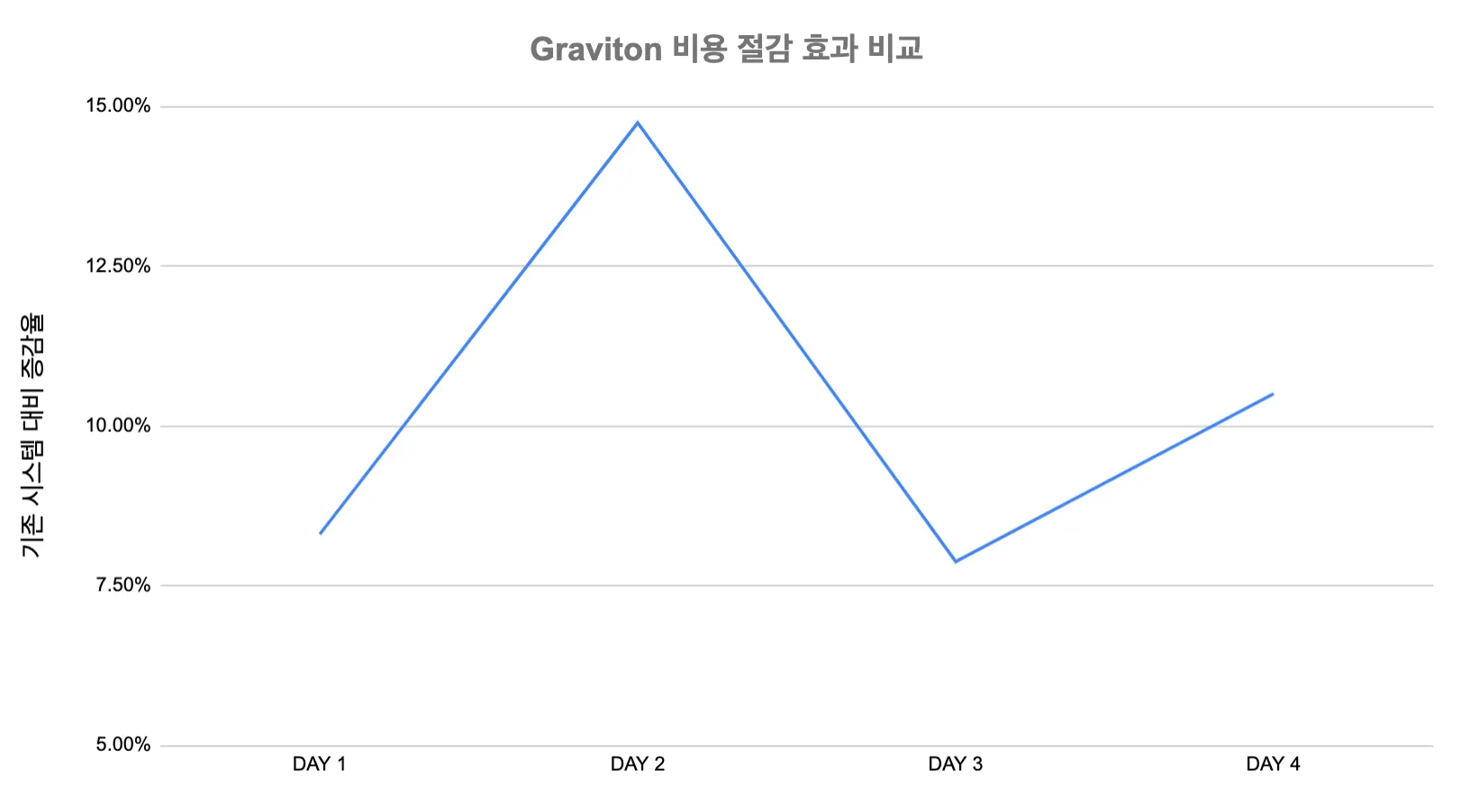
•
성능 향상
◦
Graviton2 도입 이후 Traffic Spike 발생 시 5xx 오류가 더 적게 발생하는 것을 체감할 수 있었습니다.
단점
•
운영 복잡도 증가
◦
confluent-kafka 버전업 시 자체 Repository에서 빌드를 해야 합니다.
◦
aarch64가 기본으로 지원되지 않는 의존성을 추가하기가 어려워졌습니다.
•
CodeBuild 빌드타임의 증가
◦
ARM_CONTAINER는 CodeBuild에서 Local Cache를 제공하고 있지 않아, 기존 CI에 비해 빌드 타임이 늘어났습니다.

◦
사용자가 많지 않아서인지 CodeBuild의 QUEUED Phase의 소요 시간이 현저히 긴 모습을 보였습니다.
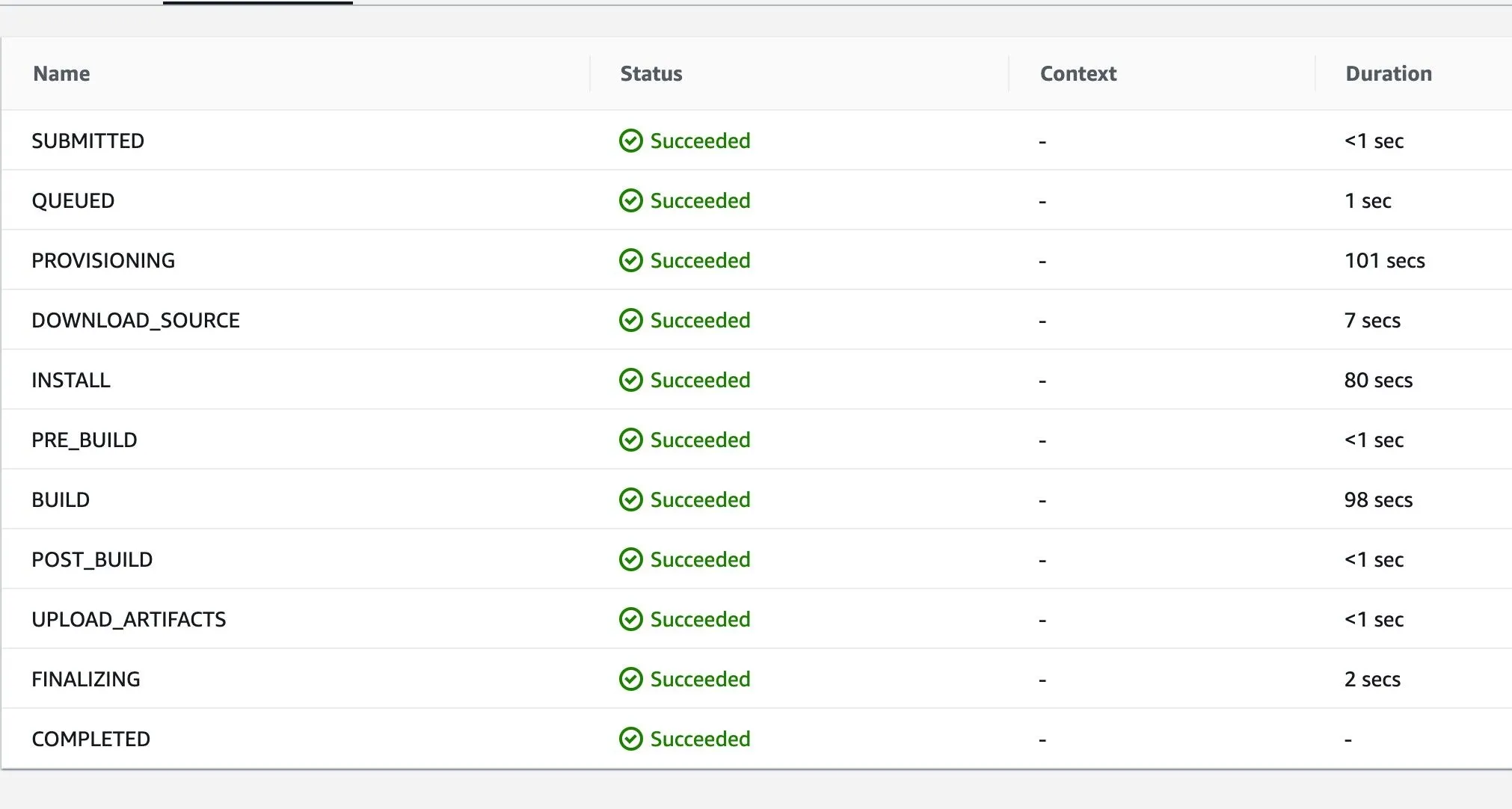
기존 x86 CodeBuild Job의 Phase별 소요 시간. QUEUED Phase에서 소요된 시간이 1초임을 확인할 수 있다.
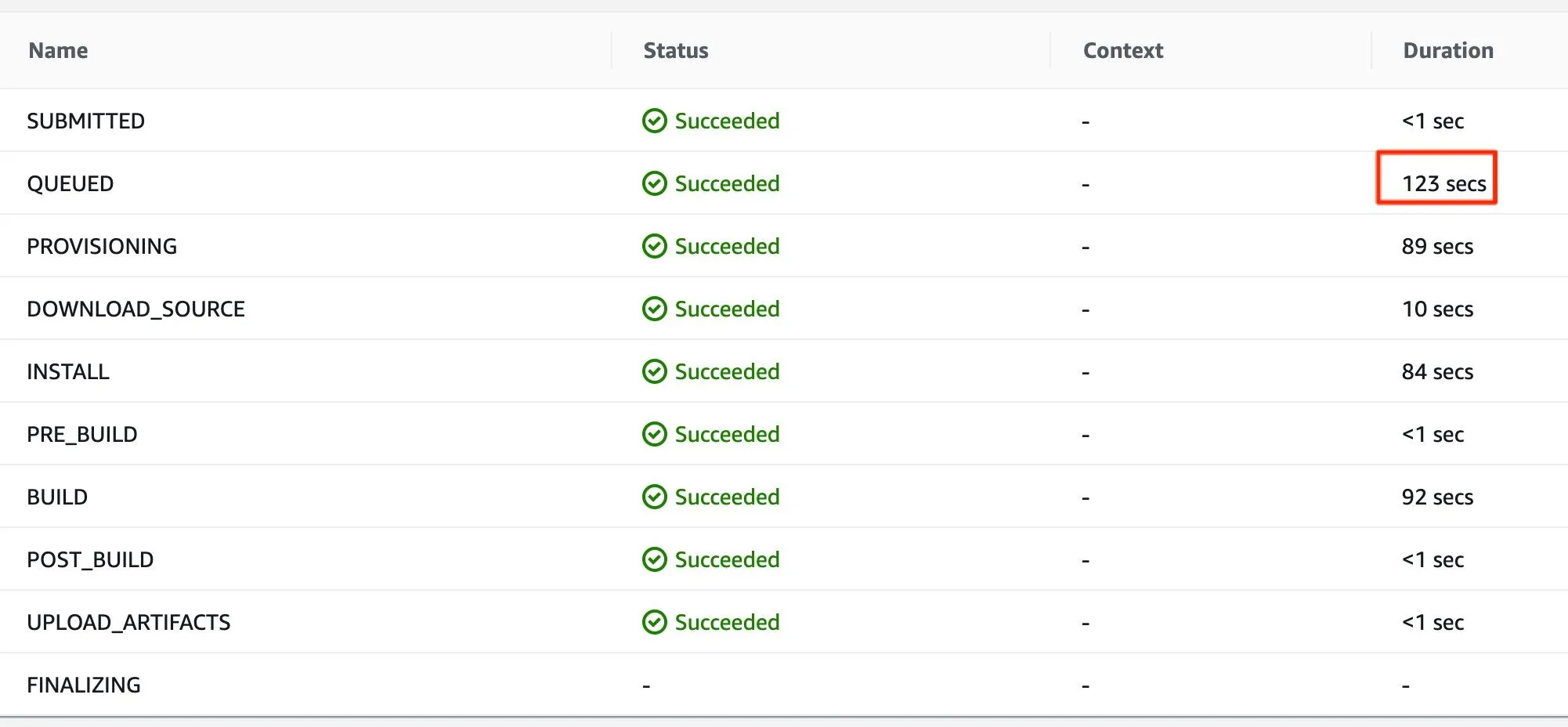
신규 ARMv8 CodeBuild Job의 Phase별 소요 시간. QUEUED Phase에서 소요된 시간이 기존 1초에서 123초로 증가한 것을 확인할 수 있다.
워크로드가 아키텍처 의존적이지 않다면 Graviton2 인스턴스는 충분히 매력적인 인스턴스 타입입니다. 비록 인프라 복잡도가 증가할 수 있다는 단점이 있지만, 절약되는 컴퓨팅 비용과 성능상의 이점은 해당 단점을 상쇄하고도 남는다고 생각합니다.
이번 글이 추후 Python 애플리케이션을 ARM으로 이전하는 개발자분들에게 많은 도움이 되길 바라며 글을 마치겠습니다.
레퍼런스





ᴡʀɪᴛᴇʀ

