

Intro
몇 년 전만 해도 Serverless 라는 것은 생소한 개념이었는데 이제는 많은 곳이 활용하는 기술이 됐습니다. 그렇지만 여전히 많은 분이 익숙하지 않은 기술이기도 합니다. Serverless는 말 그대로 항시 서버를 띄워두지 않아도 자동으로 infra가 provision 되고 실행할 수 있게 해주는 기술을 말하는데, 가끔 한 번씩 실행되어야 하는 workload에 대해 특히 유용합니다. 여기서 더 나아가 계속해서 실행되는 workload(API 서버 등)에서도 널리 쓰이는 추세로 흘러가고 있습니다.
이번 글에서는 Serverless 환경을 편하게 구축하는 데 많은 도움을 주는 Serverless framework와 Airbridge의 Data Pipeline에서 Serverless를 유용하게 사용하고 있는 사례들을 소개해보려고 합니다.
Data Pipeline에서 Serverless 기술 도입 배경
사실 예전부터 Airbridge에서는 serverless 기술을 활용하고 있었습니다. 예전에 송윤섭님이 AWS Summit에서 발표도 진행했었는데요. API 서버를 Zappa로 packaging 하여 프로덕션에서 사용 중이었습니다. Zappa에 대해서는 후술할 Serverless framework에서 좀 더 다루겠습니다.
Data Pipeline에서 Serverless 기술을 활용하기 시작한 것은 대략 2019년도 즈음부터였는데 여기에는 역사적인 배경이 있습니다. 팀에서 2018년 Airflow를 처음 도입한 뒤 운영하면서 batch job 들을 Airflow로 관리하기 시작했습니다. 처음에는 Daily 혹은 Hourly 수준으로 DAG 들을 schedule 했지만, 더 짧은 주기로 코드들을 실행하고 싶다는 요구가 생기기 시작했습니다.
가장 큰 문제는 task schedule의 landing time이었습니다. 지금은 Airflow가 2 버전대로 올라가면서 scheduler의 성능이 크게 향상됐지만, 이전에는 task가 schedule 되는데 1분 이상 딜레이가 거의 항상 발생했습니다. 여러 가지 option 들을 조율했을 때 어느 정도 tuning 가능하긴 했지만, 극적인 개선은 어려웠습니다.
또 다른 문제는 운영 경험이었습니다. 당시 Airflow를 처음 도입했을 때는 운영 경험이 없었기 때문에 365/24/7 uptime을 유지할 수 있을지에 대한 확신이 떨어졌습니다. Hourly 수준까지의 schedule은 어떻게든 극복할 수 있지만 분 단위의 schedule을 잘 커버할 수 있을지에 대한 확신이 떨어졌습니다.
이때, 대안으로 선택했던 것이 Lambda였습니다. CloudWatch event rules를 활용하면 1분, 5분 단위로 코드를 실행할 수 있었고, 몇 가지 한계만 극복하면 Lambda는 굉장히 가성비 좋은 운영 환경이었습니다.
불편했던 Lambda 배포 환경
API 서버에서 Zappa를 활용하고 있긴 했지만, 내부에서는 여러 버그와 불편한 점 때문에 Zappa에 대한 아쉬움이 많았었습니다. 게다가 Zappa를 썼을 때 IaC가 잘 않된다는 점도 큰 문제점으로 생각했기 때문에 Data Pipeline에서 필요한 component를 구성할 때는 lambda packaging을 직접 하고 terraform으로 IaC를 구성했습니다.
하지만 이 방식은 이 방식대로 여러 가지 불편함이 있었습니다.
•
사소하긴 하지만 terraform apply 만으로 잘 작동하게 만들기 쉽지 않습니다. lambda resource를 잘 update 하게 하려면 zip으로 packaging 된 파일이 먼저 필요한데 이렇게 하려면 terraform에서 꽤 노가다를 해줘야 했습니다. 게다가 이렇게 했을 때 코드는 상당히 보기 불편해집니다.
•
작성해야 하는 terraform 코드의 양 자체가 많습니다. 보통 여러 aws resource를 엮어서 사용하는 경우가 많은데 terraform으로 하나하나 정의해주는 것이 상당히 불편합니다.
◦
예를 들면 Lambda 하나를 띄우기 위해 Lambda resource뿐만 아니라 IAM resource도 정의해야 합니다.
◦
CloudWatch event rule을 적용하거나 SQS를 구독하게 하는 경우 등에도 꽤 많은 resource 들을 정의하는 terraform 코드를 작성해야 합니다.
•
몇몇 static library를 활용하는 python package의 경우 amazon linux 2 환경에서 packaging을 해야만 정상 작동합니다. 예를 들어, 팀에서 사용하던 MySQL library가 이 문제에 해당했습니다. PyMySQL library를 쓰면 회피할 수 있지만 호환성에 대해 고려를 하지 않아도 되는 게 더 낫습니다.
Serverless framework 도입
대안으로 찾았던 것이 Serverless framework였습니다. Serverless framework를 활용하면 훨씬 더 적은 코드로도 Lambda를 잘 구성하고 배포할 수 있었습니다. 아주 극단적인 예시로는 serverless.yml, main.py 단 두 개의 파일만 준비하면 코드를 운영할 수 있습니다. 제가 생각하기에 중요한 장점 몇 가지를 꼽자면 다음과 같습니다.
1.
적은 양의 코드로도 잘 구성하여 운영할 수 있습니다.
•
앞서 언급한 예시와 같이 단 두 개의 파일만 있어도 됩니다.
•
CloudWatch event rule과의 integration, SQS와의 연결 등도 serverless.yml 파일을 조금 수정하면 바로 적용할 수 있습니다.
•
serverless.yml 파일을 잘 작성하면 중복 코드도 많이 줄일 수 있습니다.
2.
Build 환경이 편리합니다.
•
dockerize option을 사용하면 amazon linux 2 image의 docker container 내에서 build 합니다. 이렇게 하면 pip install을 할 때 자동으로 amazon linux 2 환경에 맞는 C library를 가져오므로 문제가 없어집니다. 물론, CodeBuild와 같이 CI 환경에서는 dockerize를 하지 않게 할 수도 있습니다.
•
virtualenv, poetry 등과 integration이 되어 있어 가상 환경을 따로 고려하지 않아도 됩니다.
•
Python이 아니라 Go와 같은 언어일 때도 크게 Build 패턴이 다르지 않습니다.
•
artifact도 자동으로 S3에서 관리해줍니다.
3.
Test 환경이 편리합니다.
•
serverless cli에서 invoke 기능을 지원하기 때문에 테스트하기 편합니다.
•
배포 환경 stage 별, 특히 local 환경도 지원합니다.
아쉬운 점
반면 이런 아쉬운 점들도 존재합니다.
1.
Plan을 볼 수 없습니다.
•
terraform에서 매우 유용한 기능 중 하나가 plan입니다. 코드가 바뀌었을 때 infra는 어떤 변경이 발생할지 미리 보여주는 기능인데 serverless framework에서는 이 기능을 제공하지 않습니다.
2.
CloudFormation의 아쉬운 점이 동일하게 존재합니다.
•
CloudFormation stack update 중 특정 실패 케이스에 대해서는 rollback이 되지 않고 cli 상으로는 에러로 인식되지도 않는 경우가 있습니다.
•
예를 들면, 배포를 실행한 사용자의 IAM 권한 부족으로 stack 내 resource로 존재하는 IAM 권한 업데이트를 실패하면 serverless deploy 명령을 다시 실행하더라도 변경이 재시도 되지 않습니다.
•
이 경우 serverless.yml을 조금이라도 변경한 뒤 다시 serverless deploy를 해야 합니다. 저의 경우 무의미한 policy를 추가한 뒤 serverless deploy를 하고, 다시 이전 상태로 serverless deploy를 실행했었습니다.
결론
아쉬운 점을 이야기하긴 했지만 Serverless framework는 단점보다 장점이 훨씬 더 큰 framework임에는 틀림없습니다. 사실 개발을 하다보면 Serverless framework의 아쉬운 점보다는 Lambda 자체로 불편한 점들 때문에 고통받는 경우가 더 많습니다.
예를 들면, 널리 알려졌던 불편한 점으로 package 크기 제한이 있습니다. 압축했을 때는 50MB, 압축 해제했을 때는 250MB 크기 제한이 있는데 꽤 자주 불편함을 경험합니다. 특히 numpy와 같은 라이브러리를 쓰고 싶은 경우 다른 무거운 라이브러리는 추가하기 어렵습니다. 크기 제한이 1GB 정도만 됐어도 대부분의 경우 문제가 없을 텐데 아쉽다는 생각이 많이 듭니다.
하지만 Lambda는 간단한 코드를 배포하고 운영하기엔 분명 장점이 많은 운영 환경입니다. 지속해서 많은 함수 실행이 필요한 경우가 아니라면 비용 효율적으로 운영할 수 있기 때문입니다.
•
2022-03-28 업데이트:
◦
Lambda 임시 스토리지가 최대 10GB로 늘어나면서 위 package 크기 제한 단점이 일부 상쇄될 수 있을 것 같습니다. 하지만 임시 스토리지에 소스 코드를 다운로드 받는 방법 등으로 엔지니어링을 해야합니다.
활용 사례
이제 Airbridge Data Pipeline에서 어떤 workload에 활용하고 있는지를 살펴보겠습니다.
사례1: Kafka Connect Manager
Kafka Connect는 Kafka로부터 데이터를 produce 하거나 consume 하여 일련의 처리를 할 수 있게 도와주는 Kafka 생태계 시스템 중 하나입니다. 저희는 Kafka message를 consume 하여 S3와 Elasticsearch에 저장하는 데 사용하고 있습니다.
저희는 Elasticsearch의 resource를 빡빡하게 관리하고 있는데, 그러다 보니 traffic이 몰리는 경우에는 bulk write에 실패하는 경우가 종종 발생합니다. 그런데 Elasticsearch sink connector의 설정상 재시도 횟수를 높게 설정해도 task가 실패로 이어지는 현상이 반복됐습니다. 이 경우 task를 restart 하면 간단히 해결되지만 이 restart를 자동화할 방법이 필요했습니다.
이때, 사용한 것이 Lambda였습니다. 5분 단위로 Lambda를 실행하고, Lambda에서는 현재 실행 중인 connector 들의 task 상태들을 확인합니다. 각 connector 별로 RUNNING 상태, FAILED 상태 task 개수를 CloudWatch metric에 남기고, FAILED 상태 task에 대해서는 error code에 따라 restart 시킵니다. error code를 고려하는 이유는 자동 재시작을 하면 안 되는 error 케이스가 있을 수 있기 때문입니다.
이렇게 Lambda를 운영하면 Kafka Connect의 connector에 대해 alarm 설정을 할 수 있고, 재시작을 자동화할 수 있으므로 유용합니다. 그런데도 월 $1도 되지 않는 비용으로 운영할 수 있습니다.
사례2: Batch Job 실행
Airflow에서 batch job 들을 관리하고 있긴 하지만 현재 팀에서 Airflow에는 비즈니스 로직을 거의 두지 않는 방식으로 운영하고 있습니다. Airflow가 scalable 한 시스템이긴 하지만 큰 cluster를 운영하려면 고려해야 할 것이 많기도 하고, 비즈니스 로직을 Airflow DAG 코드에 두기 시작하면 너무 많은 비즈니스 로직들이 들어가서 관리하기 어려울 것 같다고 생각했기 때문입니다.
Airbridge에서는 광고 매체의 데이터를 가져와서 보여주는 기능이 있습니다. 예를 들면, 광고 매체의 비용 데이터인데요. 광고주가 Airbridge 대시보드에서 비용까지 함께 볼 수 있게 해드리기 위함입니다. 당연히 이런 경우 Airflow의 DAG으로 ETL Pipeline을 운영합니다. 문제는 데이터를 가져와야 할 광고 매체가 한두 개가 아닐뿐더러 굉장히 다양한 비즈니스 로직이 필요하다는 것입니다.
Airflow DAG에 대한 CI/CD에서 이러한 비즈니스 로직들을 모두 test 하는 것보다는 분리하는 것이 낫겠다고 판단했고, Airflow에서는 SQS에 job을 생성하면 Lambda에서 SQS message를 구독하여 데이터를 처리하게 했습니다. 이렇게 하면 Lambda의 코드에 대한 CI/CD에서 비즈니스 로직과 test를 책임지면 됩니다.
Lambda를 사용하지 않는다면 Airflow DAG에서 job queue에 message를 생성하고, EC2를 띄우거나 ECS의 service를 띄우는 식 등으로 운영해야 합니다. 하지만, Lambda를 사용하면 SQS에 message가 생성됐을 때 자동으로 Lambda를 trigger 하게 할 수 있습니다. Airflow DAG에서는 SQS에 visible message가 더 이상 존재하지 않을 때까지 기다리면 됩니다.
Serverless framework에서는 SQS event trigger 구성을 매우 쉽게 설정할 수 있게 해뒀습니다. 아래와 예시와 같이 events에 SQS를 연결해주기만 하면 됩니다. 자세한 설정은 공식 문서를 참고 부탁드립니다.
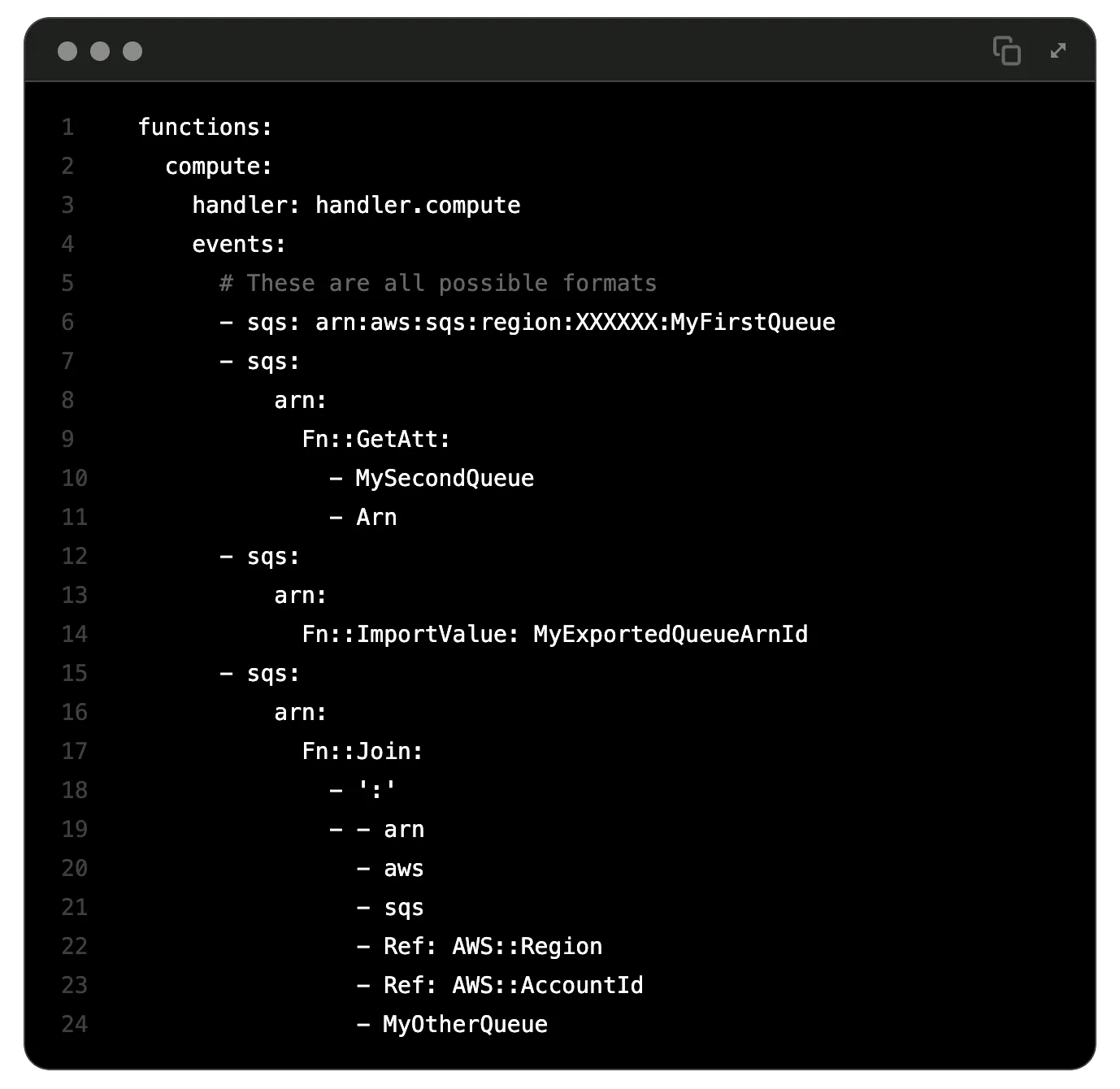
이렇게 하여 마찬가지로 매우 저렴한 비용으로 광고 매체 데이터를 가져와서 연동하는 batch job을 운영하고 있습니다. 대신 이런 운영 시 고려해야 할 점들이 있습니다.
1.
Idempotent 한 작업인지 고려가 필요합니다.
•
Lambda에서 정상적으로 실행을 마치지 않으면 SQS message가 unvisible 상태가 됐다가 다시 receive 하게 됩니다.
•
SQS standard queue를 사용한다면 마찬가지로 중복 문제가 발생할 수 있습니다. 한 message를 여러 Lambda에서 동시에 처리할 수 있기 때문입니다. FIFO queue를 활용하면 극복할 수 있는 문제이긴 합니다.
•
이러한 경우들을 고려하여 message를 재처리할 때 side effect가 없는지, 만약 side effect가 있다면 어떻게 극복할 것인지 고려를 반드시 해야 합니다. 그렇지 않으면 데이터 중복 문제 등이 발생할 수 있습니다.
2.
Max batch size에 대한 고려가 필요합니다.
a.
max batch size를 1로 지정하여 message를 한 개씩만 처리하게 했다면 고민할 필요가 없습니다.
b.
하지만 2 이상의 값으로 지정하면 batch에 대해 partial success 한 경우 대응이 필요할 수 있습니다.
3.
Reserved concurrency에 대한 고려가 필요합니다.
•
concurrency가 무한정 증가하면 side effect가 발생할 수 있으므로 reserved concurrency로 제한을 추가하는 경우가 많습니다.
•
Lambda 내부 동작상 SQS로부터 message를 polling 하는 thread는 따로 존재합니다.
•
SQS로부터 message는 polling 했지만, reserved concurrency에 의해 실행할 수 있는 Lambda가 없는 경우 해당 message는 처리 실패합니다.
•
message 처리 시간이 들쭉날쭉한 경우 Lambda timeout을 최대 시간인 15분으로 지정하는 게 보통입니다.
◦
Lambda timeout보다 SQS visibility timeout이 같거나 더 커야 하므로 마찬가지로 visibility timeout을 15분으로 지정합니다.
◦
처리 실패한 message는 15분이 지난 뒤에야 처리할 수 있으므로 queue에 저장된 message를 모두 처리하는데 시간이 더 오래 걸리게 될 수 있습니다.
•
10 미만 정도로 낮은 reserved concurrency를 두는 경우 이 현상은 굉장히 자주 발생합니다.
•
reserved concurrency 문제로 처리하지 못한 경우에는 무조건 재시도해야만 하므로 idempotent 하게 message를 처리할 수 있게 하는 것이 강제됩니다.
마치며
지금까지 AWS Lambda를 쉽게 구성할 수 있게 도와주는 Serverless framework와 Airbridge Data Pipeline에서 어떻게 활용하고 있는지에 대한 사례들을 살펴봤습니다. 여러 가지 까다로운 점들이 있긴 하지만 잘 활용하면 분명 유용한 운영 환경임에는 틀림없습니다.
그래서 Airbridge에서도 이미 꽤 많은 workload를 이렇게 운영하고 있긴 하지만 앞으로도 더 많은 workload를 운영할 계획을 하고 있습니다. 예를 들면, 앞서 설명한 Kafka Connect에서 S3에 저장하는 데이터들에 대해 S3 Event Notifications를 활용하여 event driven으로 처리할 수 있는 시스템 등이 있습니다.
앞으로도 더 재미있는 serverless workload를 소개할 수 있기를 기대해봅니다.
ᴡʀɪᴛᴇʀ
Juhong Jung @toughrogrammer
Backend Software Engineer

