

직렬화 포맷과 압축을 통해 용량 절약하기
Byeonghoon Yoo — 유병훈
@isac322
디퍼드 딥링크 기능 제공을 위한 Elasticache의 메모리 사용량을 52%, 비용을 66% 절약하는 최적화 작업을 설명합니다. 최적화 대상을 찾은 과정부터 실제로 Elasticache 이주하는 전반적인 과정과, 더 최적화한다면 어떤 선택지가 있을지 소개합니다. 개별 크기가 작은 대신 많은 데이터를 Redis에 효과적으로 저장하는 방법과, 하나의 모델을 두 서비스가 공유하는 방법에 대해서 다룹니다.
1. 발단
광고 클릭 이벤트 저장과 관련된 작업을 하다가 Redis에 데이터를 JSON 형태로 압축 없이 저장하는 것과, 그 이벤트는 광고 클릭마다 쌓이기 때문에 양이 아주 많다는 사실을 알게 됐습니다. 평소에도 해당 Redis의 메모리 사용량에 대한 PagerDuty를 새벽 6시에 가끔 받은 기억이 있어서 줄여보면 좋겠다는 생각을 하게됐습니다. 또한 하나의 Redis를 두 서비스에서 공유함에도 JSON schema 없이 각자 코드에서 본인에 맞게 모델을 정의한 문제도 발견했습니다.
광고 클릭 이벤트의 특성상 갑작스럽게 traffic spike가 발생할 수 있으므로 cache.r6g.2xlarge 2~8대를 사용했고 비용 절감을 목적으로 작업을 시작했습니다.
2. 예측과 가설
현재 상태는 잘 파악했기 때문에 앞으로 어떻게, 얼마만큼 절약할 수 있는지 예측해야 합니다.
2.1 데이터
먼저 데이터의 특성을 봐야 하는데, nested object 형태이고 한 레코드의 크기가 JSON 기준으로 1KB내외입니다. 또한 광고 클릭 이벤트가 정말 많으므로 레코드마다 1시간의 TTL을 지정함에도 불구하고 Redis에는 순간 최대 1.1억 개 이상의 레코드가 저장되어 있습니다.
2.2 직렬화 포맷
기존에는 JSON 포맷을 사용했으나, 사용량 압축 및 Schema 관리를 용이하게 하기 위해 컴파일되는 Protobuf를 사용하기로 했습니다. 만약 해당 데이터가 한 서비스에서만 사용될 것이 확실했다면, 더 높은 효율을 위해 언어에 특화된 직렬화 포맷도 고려했을 것 같습니다. (golang이라면 encoding/gob, python이라면 pickle)
2.3 압축 알고리즘
직렬화 포맷뿐 아니라 압축까지 해서 Elasticache 사용량을 더 줄이려고 했습니다. 해당 데이터는 통계를 위해 사용하거나 디버깅, 이슈 대응 때 쓰이는 데이터가 아니라서 사람이 보기 편한 것 보다 저장 효율이 더 중요하다고 판단하여 압축하기로 결정했습니다.
고려했던 알고리즘은 아래와 같습니다.
•
zstd
•
snappy
•
zlib
•
zopfli
•
brotli
2.4 벤치마크
벤치마크에서 중요한 건 데이터라고 생각하는데, 의미 없는 데이터를 넣으면 의미 없는 결과가 나옵니다. 그 때문에 실제 저장되고 있는 데이터를 수집해서 각 압축 알고리즘과 구현체를 비교했습니다. 다행히 저희는 시나리오 테스트에서 수집해 놓은 데이터가 있으므로, 시나리오에 기록되어 있던 데이터를 활용했습니다.
우선 JSON와 Protobuf를 비교해 보니, 기존 저장공간의 76.54%만 사용해서 같은 데이터를 저장할 수 있음을 확인했습니다. (즉, 기존 사용량 중 약 1/4을 없앨 수 있음)
다음으로 압축 알고리즘을 비교해야 했는데, 알고리즘은 같더라도 구현체마다 압축 효율의 차이가 있음을 확인했습니다. 저장하는 쪽 서비스는 golang으로 만들어졌기 때문에 아래의 구현체를 비교했습니다.
•
zstd
◦
github.com/klauspost/compress/zstd
◦
github.com/valyala/gozstd
•
snappy
◦
github.com/klauspost/compress/s2
•
zlib
◦
github.com/4kills/go-zlib
◦
github.com/klauspost/compress/zlib
◦
github.com/4kills/go-libdeflate/v2
•
zopfli
◦
github.com/google/zopfli
•
brotli
◦
github.com/google/brotli/go/cbrotli
◦
github.com/andybalholm/brotli
2.4.1 압축률
각 알고리즘에서 가장 압축률이 좋은 구현체를 선택해서 압축률을 비교했을 때, brotli > zopfli > zlib > zstd > snappy 순이었습니다. brotli의 최고 압축률 옵션을 선택했을 경우 JSON일 때를 기준으로 저장공간의 43.95%만 사용하도록 압축할 수 있었습니다.
같은 알고리즘이더라도 구현체가 여러 개 있는데, 크게 순수 go 구현체와 기존 C 구현체의 golang binding 두 가지로 나눌 수 있습니다. golang 커뮤니티에서는 순수 구현체를 선호하는 경향이 있어 보였지만, 실제로 비교해 보니 아무래도 C 구현체의 압축률과 수행시간을 따라갈 수는 없었습니다. 저희는 성능이 우선이었기 때문에 후자인 github.com/google/brotli/go/cbrotli 를 최종적으로 선택했습니다.
2.4.2 수행 시간 & 압축 옵션
사실 압축 옵션에 따라서 같은 구현체라도 수행 시간은 크게 달라질 수 있습니다. 저희의 경우 압축률이 가장 중요한 지표이면서, 압축 수행 시간은 서버 성능에 영향을 거의 끼치지 않았습니다. 그 때문에 수행 시간은 덜 중요한 지표였고, 정말 심각하게 느려지는 게 아니라면 용납할 수 있었습니다. 그래서 압축률이 가장 좋은 brotli를 사용한다는 것을 기반으로 어떤 옵션을 쓰는 게 효율이 높을지 고민했습니다. 또한 저희는 write intensive workload라서 직렬화 수행시간을 좀 더 주요하게 봤습니다.
수행시간 JSON 대비 사용량
JSON 1716 ns/op 100.00%
Protobuf 435 ns/op 76.54%
Protobuf + Brotli (level 3) 16877 ns/op 51.53%
Protobuf + Brotli (level 4) 16593 ns/op 48.86%
Protobuf + Brotli (level 5) 16968 ns/op 45.61%
Protobuf + Brotli (level 6) 30783 ns/op 45.61%
Protobuf + Brotli (level 7) 32626 ns/op 45.47%
Protobuf + Brotli (level 8) 32955 ns/op 45.47%
Protobuf + Brotli (level 9) 35667 ns/op 45.41%
Protobuf + Brotli (level 10) 641491 ns/op 44.42%
Protobuf + Brotli (level 11) 906785 ns/op 43.95%
Protobuf + Zopfli 145159905 ns/op 47.94%
Plain Text
복사
Brotli의 압축 레벨 11은 압축률이 가장 좋지만 너무 느렸고, 특히 5 이상이면 기존 JSON보다 10배 이상 느려지기 때문에 5를 선택했습니다.
Brotli는 sliding window 기반 알고리즘이라서 window 크기가 압축률에 영향을 주며 설정도 할 수 있는데, 저장하는 데이터가 1KB 내외라서 11을 선택했습니다. window 크기 또한 여러 값을 벤치마크했는데, 실제로 11 초과부터는 압축률 개선이 없음을 확인했습니다.
2.5 Key 압축
지금까지는 Redis에 적재할 Key-Value 쌍의 value에 대한 압축이었다면, value보다는 크기가 작지만, key 또한 압축할 수 있음을 확인했습니다. 저희는 key로 UUID를 사용했고, 기존에는 xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx 처럼 16진수 문자열 형태 그대로 입력했습니다. 그 때문에 레코드 하나당 총 36B를 사용했는데, 이는 사람이 읽기 편하게 표현하는 방식일 뿐이고 실제로는 16B만 있으면 그 값을 저장할 수 있습니다. 20B면 별 차이 없어 보이지만, 20B 1.1억 개가 모이면 2GB가 넘습니다.
다만 binary 형태 그대로 저장하면 나중에 GUI Client 등으로 검색할 때 번거로워지기 때문에 Ascii85를 사용했고, 20B로 저장했습니다.
2.6 Redis 저장 방식
1.
저희의 경우 항상 레코드 전체가 필요했기 때문에 Protobuf를 사용하는 것 보다 기능상 이점이 없었고, 무엇보다 메모리 사용량이 더 높았기 때문에 쓸 수 없었습니다.
2.
위에서 확인했던 Protobuf + Brotli의 압축 효과와 더불어 Redis 내부에서도 데이터 압축의 효과를 볼 수도 있었지만, 가장 큰 문제는 레코드마다 1시간의 TTL을 꼭 붙어야 한다는 제약조건이 있었습니다. Redis에서는 Hash의 각 하위 key마다 서로 다른 TTL을 지정할 수 없으므로 사용할 수 없었습니다.
검토해 본 결과 더 최적화할 수 없어서 기존과 같이 String 타입을 사용했습니다.
종합적으로 메모리 사용을 기존보다 1.8~2배 압축할 수 있고, 트래픽에 대입해 보면 Elasticache 비용을 68% 아낄 수 있다고 판단해서 작업을 시작했습니다.
3. 이주 계획
위에서 계획한 대로 이주할 때 아래와 같은 제약사항들이 있었습니다.
1.
데이터의 개수와 총 용량이 크다.
2.
데이터 포맷과 key가 완전히 달라졌다.
•
이로 인한 동작 변경이 없는지 검증해야 한다.
3.
모든 데이터는 TTL이 설정되어 있다.
3번 덕분에 (데이터가 영구하지 않기 때문에) 기존 데이터를 migration 해야 할 수고는 덜었지만, 2번의 검증 조건 때문에 이주 자체에 시간이 좀 쓰였습니다. 위 1. 발단 에서 언급한 것처럼, 두 서비스가 오랜 시간동안 schema 없이 데이터를 읽고 써왔기 때문에 안전한지 검증해야 했습니다. 그 때문에 아래와 같은 과정으로 이주 계획을 세웠습니다.
1.
기존 Elasticache 클러스터는 그대로 두고 신규 Elasticache 클러스터를 만든다.
2.
두 서비스의 적재하는 곳에서 신규 schema를 사용해 신규 Elasticache 클러스터에 적재한다. (기존 클러스터에 적재하는 로직은 그대로 둔다)
3.
데이터를 조회하는 곳에서 두 클러스터로부터 데이터를 가져오도록 만든다. 대신 기능 자체는 기존 클러스터에서 가져온 데이터를 기반으로 실행하고, 신규 클러스터에서 가져온 데이터는 기존 데이터와 비교해서 차이점을 로깅 한다.
4.
적재할 때의 TTL만큼 시간이 지났고 차이점이 없어지면, 조회할 때 기존 클러스터와 관련된 로직을 지우고 신규 클러스터에서만 조회하도록 변경한다.
•
모든 데이터의 TTL이 N시간으로 일정했기 때문에, 3번이 배포 완료된 시점으로부터 N시간만 지나면 두 클러스터는 완벽히 같은 내용의 데이터를 가지게 된다.
5.
기존 클러스터에 적재하는 로직을 제거한다.
6.
기존 클러스터를 제거한다.
4. Schema 공유
Protobuf는 다양한 언어의 코드를 생성해 주는 protoc가 있으므로 공유를 쉽게 할 수 있습니다. 구글처럼 하나의 Protobuf repository를 만들고 모든 서비스가 한 repository를 바라보게 할 수도 있지만, 저희의 경우 아직 서비스간 schema가 자리 잡지 않았고, 이 작업은 두 서비스만 사용할 게 확실했기 때문에 한 서비스의 코드에 Protobuf를 두고 패키징해서 다른 서비스에 제공하는 방식을 선택했습니다.
Golang으로 작성된 서비스 G, Python으로 작성된 서비스 P가 있을 때, 모델에 대한 책임은 대부분의 적재가 일어나는 G에 있다고 판단해서 Protobuf와 함께 패키징 코드를 G에 뒀습니다. 그 때문에 G에 있는 Protobuf가 변경되면 G의 CI에서 컴파일된 Python 패키지를 빌드 후 사내 PyPI에 업로드하도록 구성했습니다. P에서는 패키지 버전만 올리면 변경된 모델을 사용할 수 있습니다.
5. 장애물들
5.1 기술 부채
5.2 IAM 기반 ACL
이번 작업의 부수적인 목표가 ACL 적용을 통한 Redis 접근이었습니다. 기존엔 ACL이 없어서 접근 자체가 위협일 수 있어, 네트워크 레벨에서 머신 외에는 접근이 불가능한 상태로 운영중이었습니다. 그 때문에 개발자는 디버깅을 위한 단순 조회도 불가능했습니다. 이번엔 Elasticache 클러스터를 새로 생성하기 때문에, 처음부터 ACL을 적용하면 개발용 readonly 계정을 개발자가 할당받고 접근 허용을 받을 수 있었습니다.
Elasticache는 Redis의 비밀번호 기반 인증과 더불어 AWS IAM 기반 인증을 추가로 지원합니다. IAM 기반 인증을 사용하면 비밀번호를 생성하고, 어딘가 저장하고, 서비스 컨테이너에 주입하지 않고도, 서비스 컨테이너의 AWS 계정 & 역할을 통해 직접 인증할 수 있습니다. 이것을 적용해서 하루 정도 잘 사용하고 있었는데, 어느 순간 조회하는 API가 타임아웃이 발생해서 확인해 보니 IAM 기반 인증이 원인이었습니다. 어느 순간 WRONGPASS로 Redis client들이 접근에 실패하고, redis golang 라이브러리의 재시도 때문에 많은 커넥션이 Redis 서버에 쌓이면서 조회 또한 느려져서 발생한 문제였습니다. IAM 기반 인증을 배포한 지 26시간이 지나서 인증 토큰의 TTL 때문은 아니었던 것 같았고, 다른 원인을 찾아봐야 했습니다. 하지만 작업 목표를 생각했을 때, 비밀번호 대비 IAM 기반 인증의 편의성은 부수적인 목표라서 빠르게 딥다이브를 포기하고 비밀번호 기반 인증을 선택했습니다.
6. 결과
사용 메모리의 압축률은 처음 예측치인 1.81~2배보다 약간 더 우수한 2.08배를 달성했습니다.
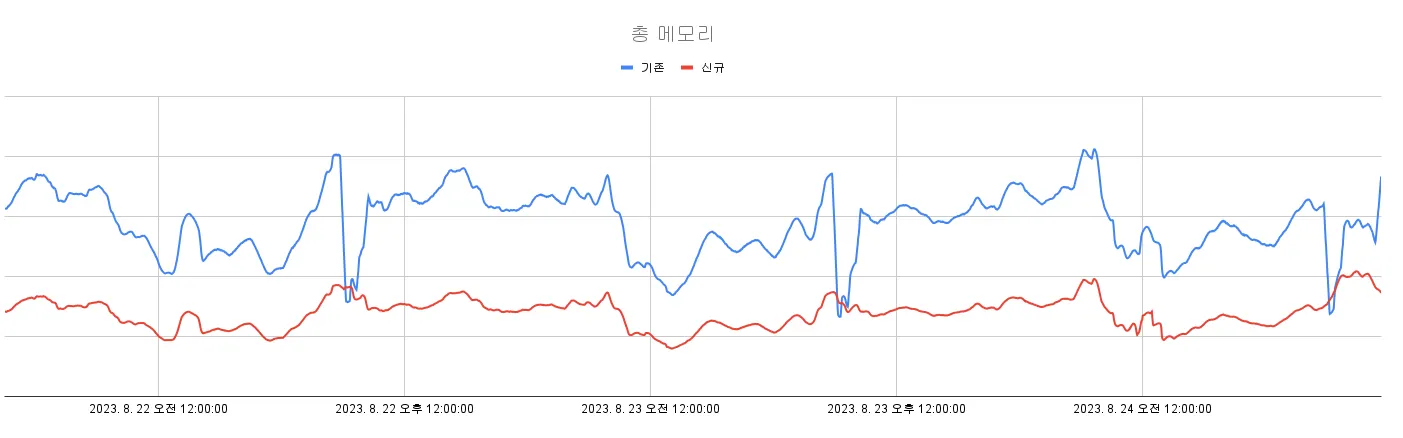
전체 노드의 메모리 사용 총량
기존보다 메모리 사용량이 절반 이하로 줄었기 때문에 cache.r6g.2xlarge 보다 절반 크기의 cache.r6g.xlarge를 사용하는 게 오히려 이점이 많다고 판단해서 스케일 다운했습니다.
인스턴스의 개수가 곧 비용이지만 인스턴스 크기가 줄어서 공정한 판단이 어려우므로 과거 메모리 사용량 데이터를 기준으로 필요한 인스턴스 수를 예측하면 아래와 같습니다. 결과적으로 비용은 66.26%를 절약했습니다.
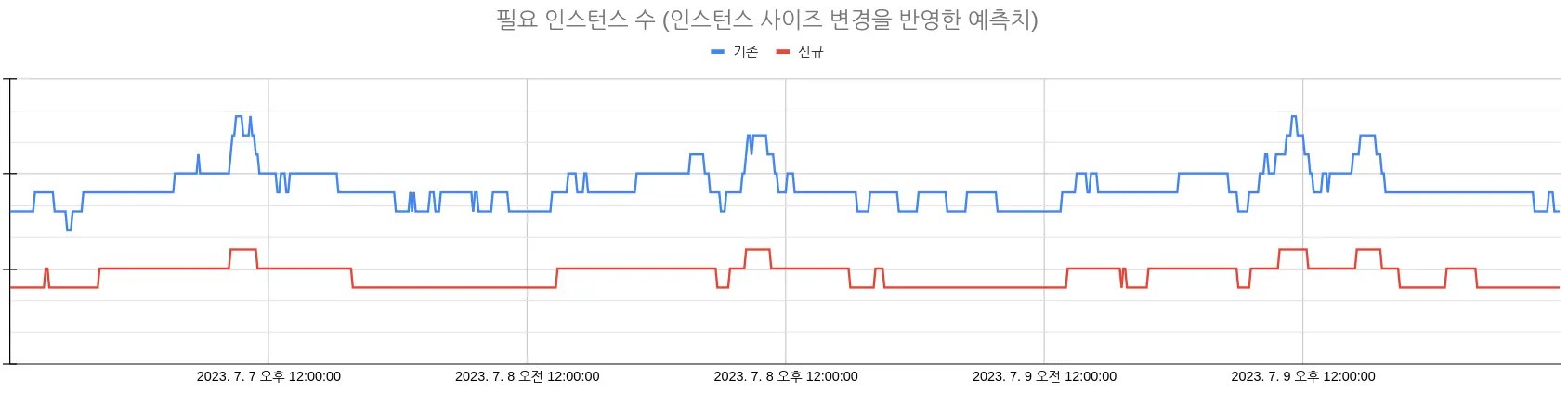
필요 인스턴스 수 (인스턴스 사이즈 변경을 반영한 예측치)
당연한 분석이지만, 레코드당 크기와 메모리 사용량의 표준편차 또한 절반 이하로 줄었기 때문에 트래픽 스파이크로인한 스케일 아웃에 좀 더 안전하게 대응할 수 있게 됐습니다.
7. 추가 최적화 거리
7.1 불필요한 데이터 쌓지 않기
저희의 경우 Redis에 특정 키가 있다/없다 2가지 말고도 “있지만 이미 조회했다”라는 상태도 기억해야 하는데, 이것을 위해 조회한 key에 대해서는 value의 특정 flag를 set 하는 방식으로 구현했습니다. 구현은 간단하지만, value에서 해당 flag를 제외하면 모두 필요 없는 값을 TTL 동안 메모리에 저장하기 때문에 상태 저장 방식을 바꾸면 메모리를 더 아낄 수 있습니다. 저희의 경우 이 작업으로 인한 아낄 수 있는 메모리가 크지 않아서 이번에 같이 작업하지 않았습니다.
7.2 TTL이 지난 레코드 더 자주 회수하기
Redis는 기본적으로 TTL이 지난 모든 레코드를 실시간으로 제거하지 않습니다 (공식 문서). INFO command 출력의 expired_stale_perc 을 보면 회수되지 않은 레코드의 비율을 볼 수 있습니다. 주기를 짧게 해서 회수량을 늘리면 메모리는 아낄 수 있지만 대신 그만큼 CPU를 사용하기 때문에 고려하여 설정해야 합니다.
7.3 Elasticache의 데이터 계층화 노드 사용하기
cache.r6gd.xlarge와 같이 d 가 붙은 노드는 SSD가 붙어서 사용되지 않는 데이터를 SSD로 옮김으로써 더 많은 저장공간을 사용할 수 있습니다. cache.r6g.xlarge는 메모리만 26.32GB 사용할 수 있지만, cache.r6gd.xlarge는 여기에 SSD 99.33GB를 더해서 총 125.65GB를 사용할 수 있는 대신 가격이 2배 약간 안 되게 비쌉니다. 용량당 비용을 생각하면 60% 정도 저렴하므로 데이터가 충분히 크고, 읽기 비율이 낮고, 읽을 때 SSD 읽기 정도로 느려도 된다면 충분히 좋은 선택지가 될 수 있습니다.
8. 마치며 (요약)
•
동일한 원본 데이터의 저장 방식을 바꿔서 Elasticache의 메모리 사용량을 52%, 비용을 66% 절약했습니다.
•
JSON대신 Protobuf를 사용해서 데이터 스펙을 명시함과 동시에 서비스간 데이터 읽기/쓰기 방식을 통일했습니다.
•
저희의 경우 (1KB대의 작은 데이터) zstd, snappy, zlib, zopfli, brotli를 비교했을 때 brotli가 가장 높은 압축률을 보였습니다.
•
brotli에서 window 크기와 압축 레벨에 따른 소요시간과 압축률을 비교해서 최적값을 찾았습니다.
•
UUID를 Redis의 key로 사용할 때 ascii85를 사용해서 메모리 사용량을 조금이나마 절약했습니다.
•
도메인 관련 기술 부채가 인프라에 대한 비용 절감 작업의 장애물이 될 수 있음을 인지하고, 명시적인 schema로 이를 청산했습니다.
9. 참고 자료
ᴡʀɪᴛᴇʀ
Byeonghoon Yoo @isac322
Backend Engineer @AB180

