
개요
AWS ECS는 꽤 편리하고 생각보다 여러 곳이 사용하고 있는 운영 환경입니다. 그런데도 클라우드 환경에서는 매우 중요한 Auto Scaling과 관련하여 아쉬움이 많았던 서비스인데요. 트래픽이 갑자기 spike 치는 일이 종종 발생하는 Airbridge 워크로드에서는 고통이 꽤 컸었습니다. Auto Scaling이 잘 안되면 비용이 많이 낭비되기 때문입니다.
이번 글에서는 AWS ECS Managed Cluster Auto Scaling과 비용 관련 문제점, 그리고 Airbridge Backend 팀에서 어떻게 개선했는지 소개합니다.
AWS ECS와 비용
AWS ECS는 완전 관리형 컨테이너 오케스트레이션 서비스입니다. Docker Image를 만들어두면 쉽게 배포하여 운영할 수 있게 도와줍니다. Service라는 단위에서는 여러 개의 Task 들을 관리해주고, Task 내에는 여러 컨테이너가 실행될 수 있습니다. 또한, 각 Task와 Container에 대해 컴퓨팅 리소스(CPU, Memory) 제한도 할 수 있습니다.
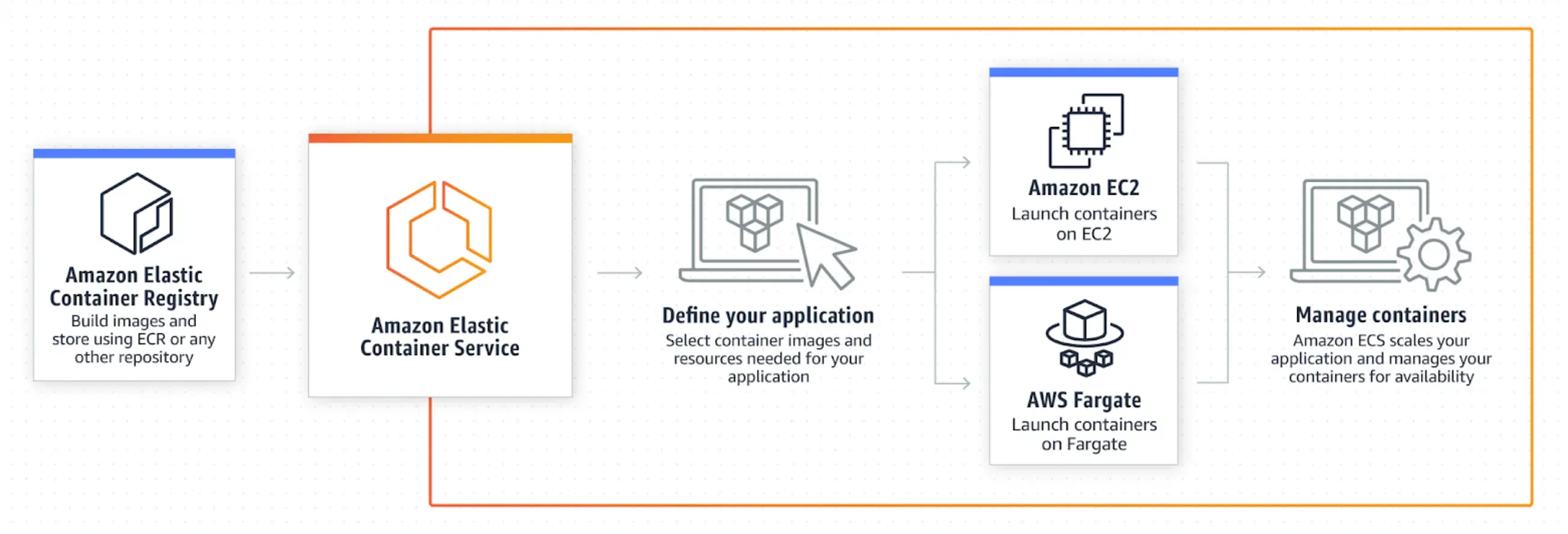
ECS에는 Fargate, EC2 두 가지의 Launch type이 존재합니다. Fargate는 서버리스 환경이지만 EC2 launch type을 사용하는 경우 EC2 instance를 직접 띄우기 때문에 관리가 필요합니다. 더 자세한 설명은 AWS 문서를 참고해주세요.
Fargate launch type의 경우 사용하는 vCPU, Memory에 비례한 비용이 들고, EC2 launch type의 경우 (당연히) 사용하는 EC2 instance에 대한 비용이 듭니다. Airbridge Backend 팀에서 ECS를 처음 도입할 당시에는 Fargate가 비교도 안 될 정도로 더 비쌌기 때문에 전혀 고려 대상이 아니었습니다. Fargate Spot도 없었기 때문에 Spot instance를 적극적으로 사용하던 저희에게 적합하지 않았습니다.
시간이 지나면서 Fargate 비용이 점점 더 저렴해졌고 관리 비용을 고려하여 다시 비교해봐야겠다는 생각이 들었는데요. 관련한 AWS 블로그 글을 봤을 때 여전히 vCPU나 Memory 사용량이 높은 경우 Fargate보다는 EC2가 저렴합니다.
EC2를 사용해서 비용 절감을 잘하기 위해서는 EC2 instance에 대한 관리가 잘 되는 것이 중요합니다. m5.4xlarge instance를 사용하면 vCPU 16384, Memory 65536을 사용할 수 있는데 그 위에서 vCPU 1024, Memory 2048짜리 task 하나만 실행되고 있다면 매우 많은 리소스가 낭비되기 때문입니다. 아주 운이 나쁜 경우에는 m5.4xlarge 여러 대에 각각 하나의 task만 실행되고 있을 수도 있습니다. 이런 때에는 task를 한 instance에 모두 옮기고 불필요한 EC2 instance를 제거하고 싶어집니다.
ECS Managed Cluster Auto Scaling
EC2 launch type을 사용하는 경우 Auto Scaling은 오래전부터 말이 많았습니다. 놀랍게도 초창기 ECS는 Cluster Auto Scaling을 직접 관리해야 했습니다. Reserved resource, Utilized resource metric이 있으니 이걸 가지고 직접 Auto Scaling Group을 관리하라는 것이었습니다.
하지만 Reserved resource metric은 auto scaling에 사용하기 편하지 않았고, 그렇다고 utilized resource metric을 활용하자니 ECS service의 metric과는 꽤 차이가 있어서 잘 작동하지 않았습니다. 말은 복잡하지만 실제로 ECS를 운영해보신 분들이라면 단번에 무슨 뜻인지 이해되실 것입니다.
Managed Cluster Auto Scaling의 작동 원리
간단하게 작동 원리를 짚어보겠습니다. Managed Cluster Auto Scaling에는 ECS의 capacity provider가 중요한 역할을 합니다. Capacity provider를 생성하면 CloudWatch에 CapacityProviderReservation라는 metric이 남고, EC2 auto scaling group이 CapacityProviderReservation metric에 대해 Target Tracking Scaling policy를 설정합니다. 이 값이 목표치에 잘 유지되도록 Auto scaling이 작동합니다.
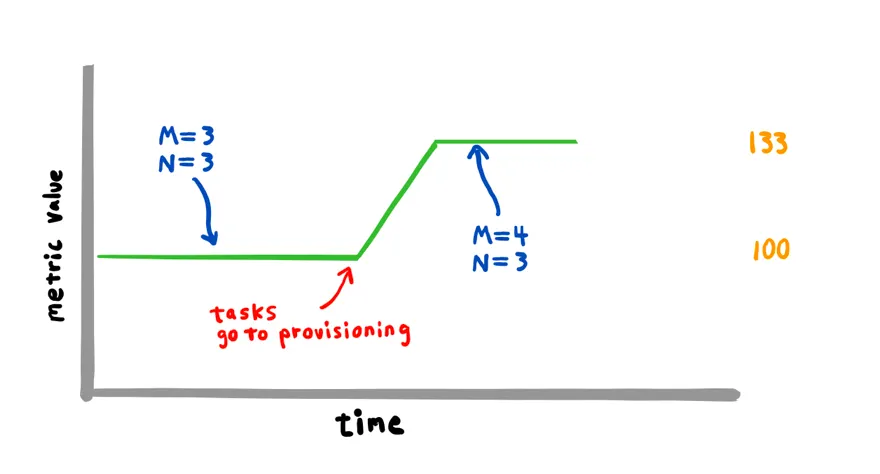
Managed Cluster Auto Scaling의 문제점
하지만 실제로 Managed Cluster Auto Scaling 기능을 써보면 만족스럽지가 않습니다. 문제가 되는 경우를 이해하기 위해 아래와 같은 상황을 생각해보겠습니다.
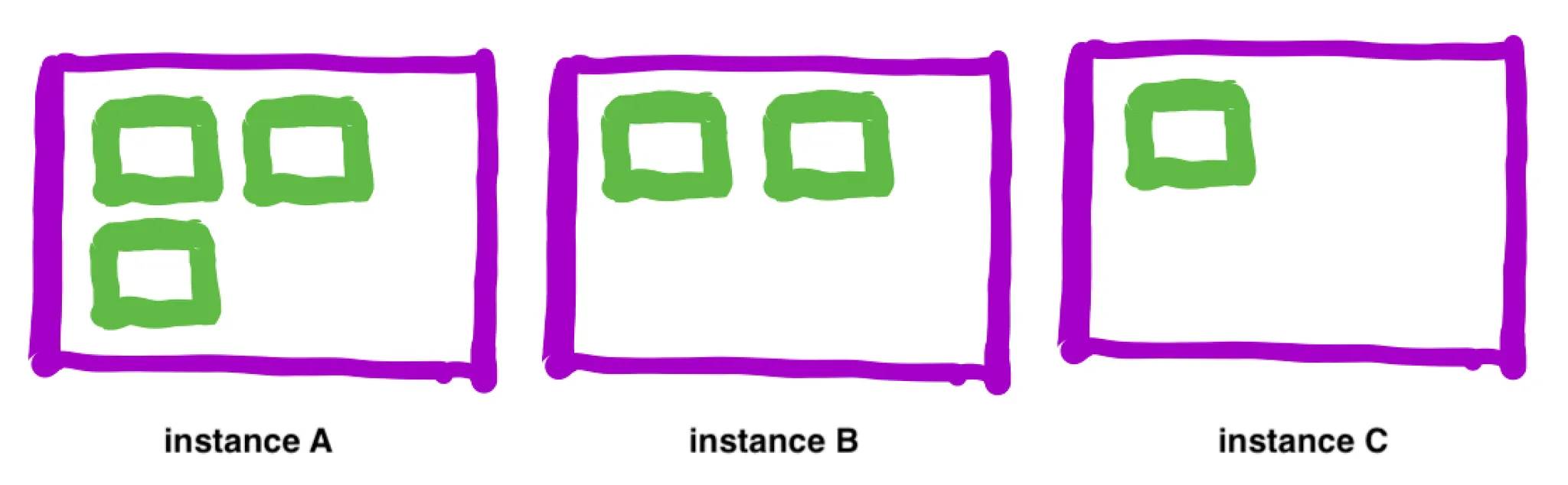
Managed Cluster Auto Scaling은 위와 같은 상황에서 instance C를 제거해주지 않습니다. Cluster의 리소스는 많이 남는 상황이지만 실행 중인 task가 있는 instance C를 종료시켜버리면 에러가 발생할 수 있기 때문입니다. 그래서 아래와 같이 instance C에 실행 중인 task가 종료된 뒤에야 instance C가 자동으로 종료됩니다.
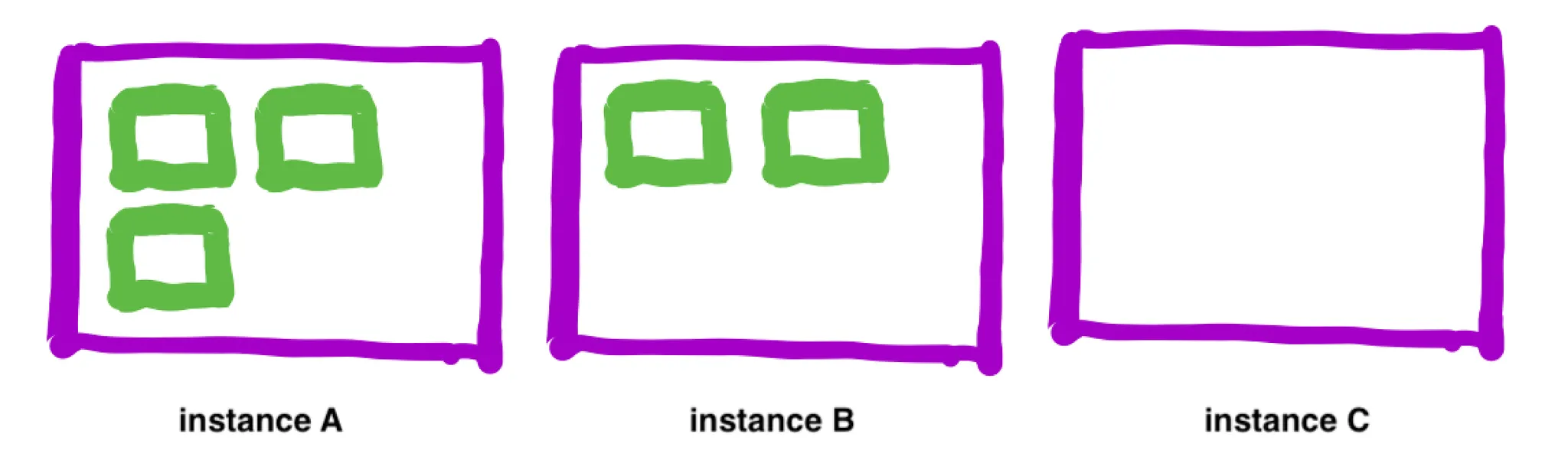
생각보다 위와 같은 상황은 자주 발생합니다. Cluster 내에 여러 service를 운영하는 게 보통이고, service마다 scale in, scale out이 제각각 일어나기 때문입니다. 극단적으로는 다음과 같은 상황이 발생하곤 합니다. Task가 모두 실행되는 데는 instance 1개로도 충분한데도 아래 상황에서는 instance 3개가 실행되는 상태가 유지됩니다.
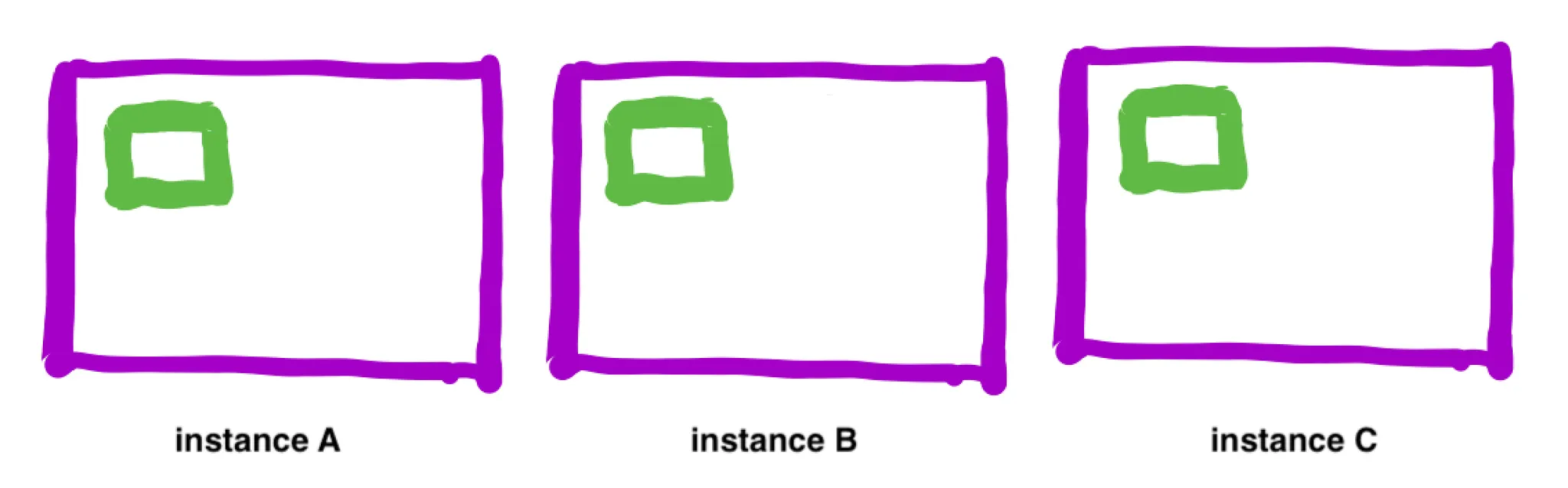
또 다른 문제점이 있는데, Scale in이 굉장히 느리게 실행된다는 것입니다. Target Tracking Scaling policy는 기본적으로 scale in을 위해 15분을 기다리기 때문입니다. 생성된 CloudWatch Alarm을 직접 수정해서 15분이 아니라 5분 정도로 줄일 수 있긴 하지만 경험적으로 EC2 instance 종료할 것은 최대한 빨리 종료하더라도 서비스 안정성이 그리 떨어지지 않을뿐더러 비용상으로도 훨씬 낫습니다.
문제 해결하기
사실 저는 Managed Cluster Auto Scaling 기능이 출시되자마자 사용해봤으나 만족스러운 auto scaling이 되지 않는 것을 보고 바로 포기했는데요. 리서치 과정에서 ECS event와 최대 리소스 크기의 task를 활용한 방법을 보고 적용해서 1년 반가량 잘 운영했습니다.
하지만 이 방법에는 ECS Cluster 내 task 중 가장 resource를 많이 사용하는 task를 계속 신경 써줘야 한다는 단점이 있었습니다. Managed Cluster Auto Scaling을 사용하면 CapacityProviderReservation metric을 이용해서 scale out이 필요한 상황인지를 쉽게 파악할 수 있습니다. 고민 끝에 Managed Cluster Auto Scaling과 ECS event를 잘 이용하면 문제를 해결할 수 있겠다는 생각에 다다랐습니다.
비용 최적화를 위해서는 Scale in이 잘 되는 것이 중요한데, scale in과 관련해서는 Managed Cluster Auto Scaling을 이용하는 게 아니라 다음과 같은 작업을 수행하는 supervisor를 따로 운영합니다.
1.
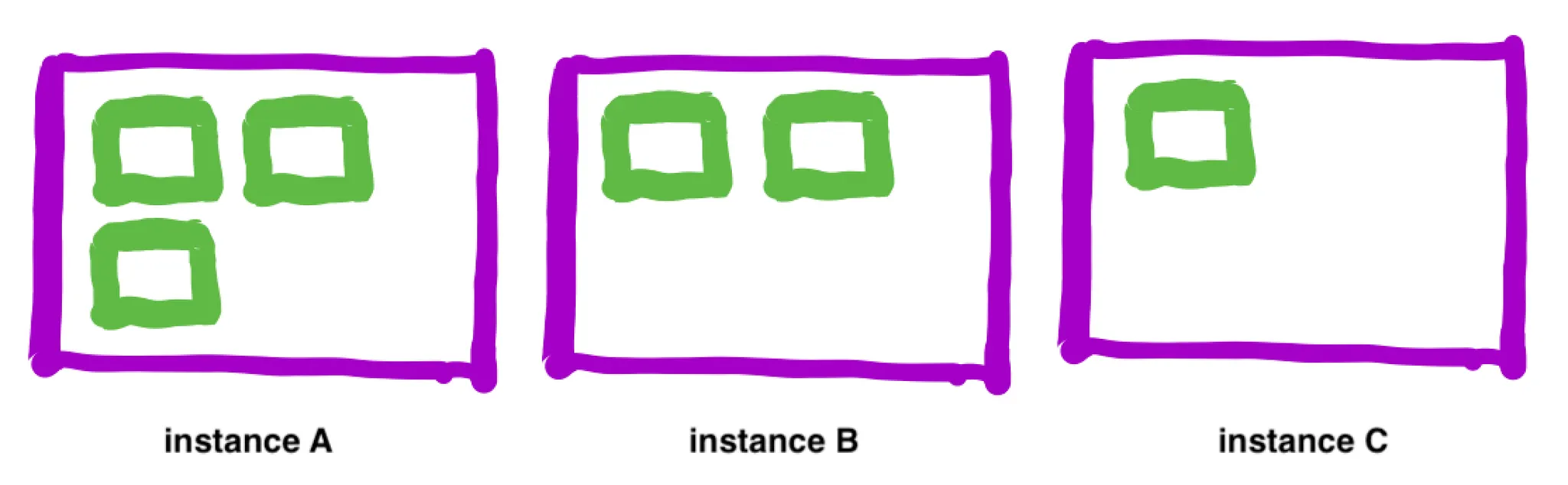
주기적으로 종료 가능한 EC2 instance를 찾아서 drain: Cluster에서 가장 resource를 적게 사용하고 있는 instance의 task들을 다른 곳으로 옮길 수 있는지 검사하고 만약 모든 task를 옮길 수 있다면 해당 EC2 instance를 drain 합니다. 아래 예시에서 instance C의 task가 instance A나 B에 옮겨질 수 있기 때문에 instance C를 drain 해도 안전합니다.
2.
즉시 종료 가능한 EC2 instance는 즉시 종료: 1에서 drain을 하는 것은 ECS task들을 안전하게 다른 EC2 instance로 rebalancing 하기 위함입니다. 앞서 언급한 것과 같이 Managed Cluster Auto Scaling을 사용하더라도 종료 가능한 EC2 instance가 종료되기까지는 기본 15분이 걸립니다.
•
ECS event 중 ECS Container Instance State Change event를 이용하면 container instance에 실행 중인 task가 변경될 때마다 실행 중인 task 개수를 확인할 수 있습니다.
•
더는 실행 중인 task가 없을뿐더러 DRAINING, INACTIVE status라면 즉시 종료 가능하다는 뜻이므로 auto scaling group의 desired capacity를 내려주고 EC2 instance를 terminate 하면 됩니다.
저는 Task들을 옮겨주고 종료 가능한 EC2 instance를 즉시 종료시켜주는 작업을 cluster compaction이라고 부르기로 했습니다. Serverless를 활용하면 Lambda 실행 scheduling이나 ECS event 구독을 쉽고 저렴한 비용으로 운영할 수 있습니다.
더 잘 작동하기 위해 추가로 필요한 것
Cluster compaction이 잘 작동하기 위해서는 가장 resource를 적게 사용하고 있는 instance가 잘 찾아질 수 있게 하는 것이 중요합니다. ECS Service의 Placement strategy를 잘 활용하면 가장 resource를 적게 사용하는 instance가 나타날 확률을 높일 수 있습니다. 평소에 Task를 어떤 instance에 실행시킬지를 placement strategy가 결정하기 때문입니다.
binpack strategy를 사용하면 task를 추가로 실행할 때는 리소스를 많이 사용하고 있는 EC2 instance에 실행하고, task를 제거할 때는 리소스를 덜 사용하고 있는 EC2 instance에서 실행 중인 task를 제거합니다. 그러므로 리소스를 덜 사용하고 있는 EC2 instance가 나타날 확률을 높일 수 있습니다.
제가 추천하는 strategy는 HA와 비용을 고려하여 availability zone은 spread, CPU/memory는 binpack으로 설정하는 것입니다. 이렇게 설정하면 ECS Service에서 새로운 task를 실행하거나, 기존 task를 제거할 때 availability zone에 고르게 분배하면서도 CPU/memory resource를 최대한 활용하는 방향으로 schedule 합니다. Multi AZ HA를 포기한다면 비용을 더 최적화할 순 있겠지만, 고가용성 서비스 운영에 사용하기엔 조심스럽습니다.
"placementStrategy": [
{
"field": "attribute:ecs.availability-zone",
"type": "spread"
},
{
"field": "cpu",
"type": "binpack"
}
]
JSON
복사
하지만 위 Strategy에 의해 rebalancing이 일어나진 않습니다. 이미 실행 중인 Task를 위 strategy에 따라 옮겨주진 않기 때문입니다. Rebalancing과 비슷한 역할을 cluster compaction이 하고 있다고 볼 수도 있겠습니다.
주의 사항
Cluster compaction이 실행되면 아무래도 기존보다는 EC2 instance가 부족해질 가능성이 더 올라갑니다. 그러므로 서비스 안정성에 문제가 없도록 ECS service auto scaling을 잘 설정해두고, 필요한 경우에는 scheduled action을 이용해서 주기적인 트래픽 spike를 잘 대응해두는 게 좋습니다.
여러 ECS Cluster 운영을 위한 양념 한 스푼
ECS cluster를 여러 개 운영하는 경우 위 알고리즘이 어떤 ECS Cluster에 적용되어야 할지에 대한 설정을 어떻게 하면 좋을지 고민될 수 있습니다. Airbridge에서는 Tag를 활용했습니다. ECS cluster 리스트를 불러오고 ECSCostOptimizerEnabled tag가 존재하는 경우에만 위 알고리즘이 실행되게 했습니다.
성과
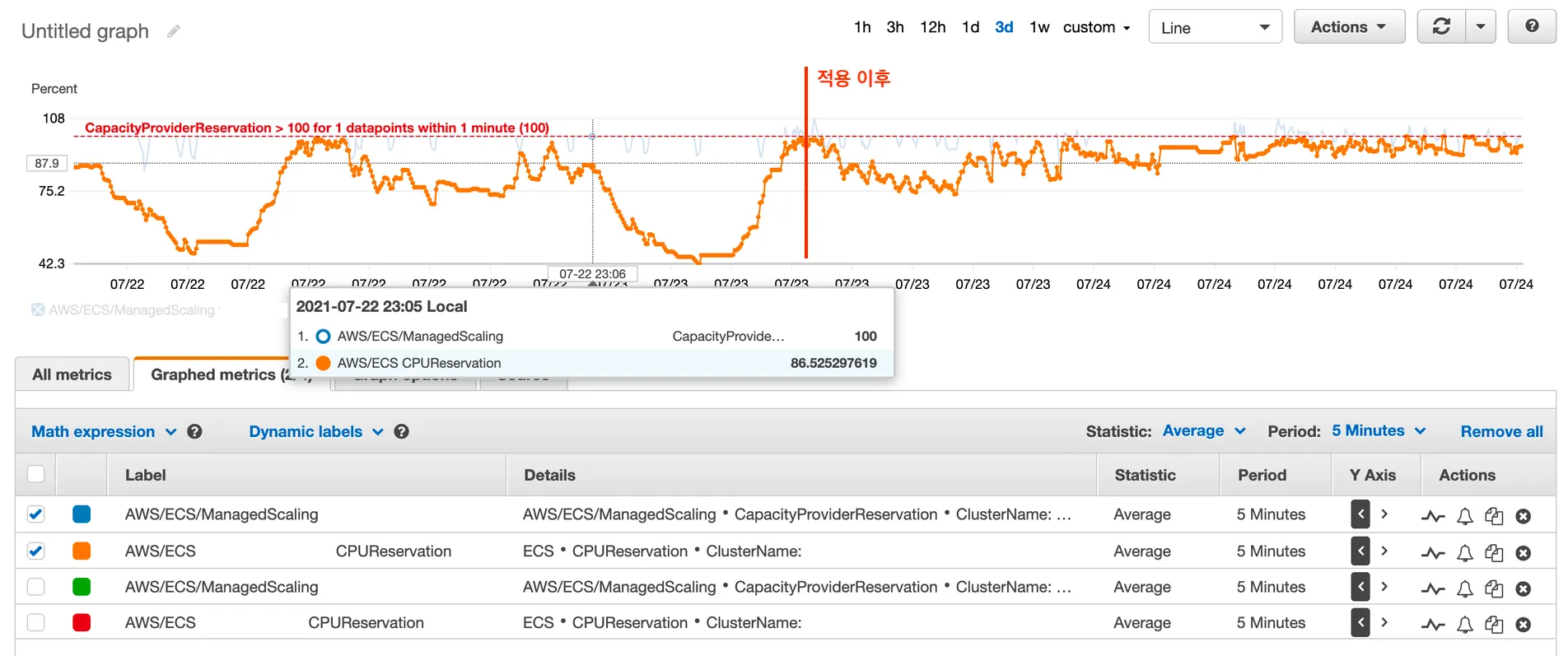
적용 이전과 이후를 CPUReservation metric으로 비교해보겠습니다. 적용 전보다 CPUReservation이 100%에 가까운 수치로 유지되는 것을 볼 수 있습니다. 실제로 EC2 비용이 20% 정도 감소한 것을 확인할 수 있었습니다. 이 알고리즘을 위한 Serverless 코드 운영에는 한 달에 $1도 들지 않았고, 서비스 안정성에도 문제없었습니다.
마치며
Airbridge에서는 비용 최적화가 매우 중요하므로 이 작업이 중요했습니다. 실제로도 20%나 비용 감소를 할 수 있었기도 합니다. 하지만 이러한 운영 환경을 가져가는 것이 모두에게 최선이라고 생각하진 않습니다. 관리 비용을 줄이고 비즈니스 로직 개발에 더 집중해야 하는 조직일 경우에는 Fargate를 잘 활용하는 게 더 나을 수도 있습니다. 이 글에서 다루진 않았지만 트래픽 유동성이 매우 크면 scaling이 잘되지 않는 문제는 여전히 존재하는데, 그런 관리 비용을 감수하지 않는 게 차라리 더 나을 수 있기 때문입니다.
미래에는 Managed Cluster Auto Scaling 기능이 더 개선되어서 이렇게 DIY로 구현한 것이 자동으로 됐으면 좋겠다는 바람과 함께 글을 마칩니다.
References
ᴡʀɪᴛᴇʀ
Juhong Jung @toughrogrammer
Product Div, Backend Group Lead

