

Jaewan Park — 박재완
@hueypark
Luft는 복잡한 OLAP 워크로드를 빠르고 효율적으로 처리하기 위해 설계된 데이터베이스 관리 시스템으로, 다양한 알고리즘과 기술을 적용하여 사용자의 쿼리를 신속하게 해결해 왔습니다. 그러나 특수한 대형 쿼리에 대해서는 아직 적절한 해결책을 찾지 못했습니다.
이 문제를 극복하기 위해, 더 고도화된 쿼리 옵티마이저와 리소스 스케줄링 메커니즘을 도입하는 것을 제안드립니다. 이는 시스템의 효율성을 크게 향상시킬 것이며, 그 결과 대규모 데이터 분석 작업에 더 뛰어난 성능을 발휘할 수 있게 됩니다.
제안서를 작성하며 저는 이 변경이 가져올 가능성에 대해 큰 기대와 흥분을 느꼈습니다. 이러한 비전을 여러분과 나누고자 합니다.
해결하고 싶은 문제
1.
복잡하고 장기간 실행되어야 하는 특수한 쿼리는 상당량의 컴퓨팅, 메모리, 그리고 I/O 리소스를 필요로 합니다. 이러한 쿼리가 예상되는 경우, 두 가지 접근 방식을 고려할 수 있습니다: 리소스를 미리 할당하거나, 쿼리 실패를 확인한 후 대응하는 것입니다. 전자는 미리 할당된 리소스의 낭비가 발생하고, 후자는 사용자 경험에 부정적으로 작용합니다. 우리는 휴리스틱한 방법으로 이 결정 사이의 절충점을 찾아내고 있지만, 최적의 방법이라 말하기는 어렵습니다.
2.
워크로드 분석을 통해, 리소스 요청이 특정 시점에 집중되는 경향이 있다는 것을 알고 있고, 우리 시스템은 이미 확장 가능하게 설계되었습니다. 하지만 그 속도가 충분하지 않아 리소스를 최대 부하에 대응할 수 있게 오버 프로비저닝하는 경향이 있습니다.
3.
지금까지 최적화 작업의 범위는 일반적인 쿼리에 한정되었습니다. 데이터의 크기와 형태에 따라 더 특화된 최적화 전략을 적용할 수 있지만, 다른 쿼리에서는 비효율적으로 작동하는 경우가 많아 적용이 어려웠습니다.
이를 다시 정리하면 아래와 같습니다:
1.
스케일링을 덜 휴리스틱한 방법으로 하고 싶다.
2.
오버 프로비저닝 하고 싶지 않다.
3.
특정 쿼리에만 적용되는 최적화를 적용하고 싶다.
이론적인 문제 해결 도구
이 문제들을 해결하기 위해, 향상된 쿼리 옵티마이저와 리소스 스케일러를 도입하는 것을 제안드립니다. 이들은 시스템의 효율성을 크게 향상시켜, 특수한 쿼리에도 뛰어난 성능을 발휘할 수 있게 합니다.
먼저 쿼리 옵티마이저는 쿼리를 실행하는 데 필요한 최적의 실행 계획을 찾아냅니다. 특히 리소스 스케일링이 필요 여부를 사전에 판단할 수 있다면, 리소스 스케일러에게 쿼리 실행을 위한 리소스를 추가로 요청할 수 있습니다.
리소스 스케일러는 쿼리 옵티마이저가 요청한 리소스를 할당합니다. 우리의 경우 순간적으로(1초 이내) 대량의 리소스를 할당받아야 하기 때문에 Serverless 서비스 중 하나를 선택할 가능성이 높습니다.
쿼리 옵티마이저
우리가 구현할 쿼리 옵티마이저를 정의하기 위해 전통적인 SQL 쿼리 옵티마이저에 대해 조금 알아보겠습니다.
간단한 쿼리를 통해 왜 옵티마이저가 필요하고, 어떻게 동작하는지 살펴봅시다.
아래 쿼리는 name 이 Huey Park 인 사용자의 event_type 이 click 인 이벤트를 조회합니다.
SELECT
*
FROM users u
JOIN events e ON
u.id = e.user_id
WHERE
u.name = 'Huey Park';
e.event_type = 'click';
SQL
복사
이 쿼리는 실제로 어떻게 실행될까요? 아래 DDL 을 바탕으로 잠시 상상해봅시다.
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL
);
CREATE TABLE events (
event_id INT PRIMARY KEY AUTO_INCREMENT,
user_id INT,
event_type VARCHAR(50) NOT NULL,
event_name VARCHAR(50) NOT NULL
);
CREATE INDEX idx_user_id ON events(user_id);
CREATE INDEX idx_event_type ON events(event_type);
SQL
복사
저는 언뜻 2가지 방법이 떠오릅니다. 각 테이블의 row 수와, cardinality 를 고려해 어떤 방법이 더 좋은지 고민해 볼 수 있습니다.
1.
users 테이블에서 name 이 Huey Park 인 사용자를 찾고, 그 사용자의 id 이용해 를 events 를 조회
2.
events 테이블에서 event_type 이 click 인 이벤트를 찾고, 그 이벤트의 user_id 를 이용해 users 를 조회
하지만 충분히 발달한 데이터베이스 시스템은 이보다 더 많은 것들을 고려하고 있습니다.
1.
Join 시 어떤 테이블을 먼저 조회해야 할까요?
2.
Hash join, merge join, ... 중 어떤 join 알고리즘을 사용해야 할까요?
3.
Where 절의 조건은 join 전에 처리되는게 좋을까요 아니면 join 후에 처리되는게 좋을까요?
4.
어떤 인덱스를 사용해야 할까요?
5.
만약 여러 테이블을 join 해야 한다면 어떨까요?
6.
etc.
실제 각각의 데이터베이스는 그 워크로드에 맞게 매우 복잡한 규칙들이 구현되어 있습니다. 이를 따라가려니 약간은 막막합니다.
하지만 모두가 어려워 하는 문제 (proven to be NP-Complete) 라는 것이 저의 마음을 약간 편하게 합니다. 우리도 우리 워크로드에 맞는 적정 수준의 옵티마이저를 구현하면 될 것 같습니다.
This is the part of a DBMS that is the hardest to implement well (proven to be NP-Complete).
No optimizer truly produces the "optimal" plan
- Use estimation techniques to guess real plan cost.
- Use heuristics to limit the search space.
Markdown
복사
옵티마이저 구현 전략은 데이터베이스마다 다양하지만 많이 사용되는 몇 가지를 살펴봅시다.
1.
휴리스틱 옵티마이저
•
미리 작성된 휴리스틱한 규칙을 사용합니다.
•
작성하기 간단하다는 장점이 있고, 많은 데이터베이스의 (Luft 를 포함해) 초기구현에 사용됩니다.
2.
휴리스틱 + Cost-based 옵티마이저
•
비용 계산 모델을 바탕으로 휴리스틱한 규칙을 적용합니다.
•
데이터베이스마다 다양한 비용 계산 모델을 사용합니다.
•
보통 휴리스틱을 빼고 Cost-based 옵티마이저라고 표현하다보니 저는 오랜기간 휴리스틱한 규칙이 아예 없어진다고 착각했습니다.
3.
이 외에도 다양한 옵티마이저 구현 전략이 존재합니다.
•
etc.
우리는 이 중 휴리스틱 + Cost-based 옵티마이저를 사용하려 하고, 구현의 세부사항은 실용적인 문제 해결 방안에서 더 알아보겠습니다.
리소스 스케일러
1.
AWS Lambda
•
장점: Luft 워크로드 대부분이 AWS 에서 동작하고 있어 적용하기 쉬움
•
단점: gRPC 지원하지 않음(좀 더 정확히 말하면 input, output 을 stream 을 쉽게 처리할 방법이 없음)
2.
Google Cloud Run
•
장점: gRPC 지원
•
단점: AWS 에서 동작하는 Luft 워크로드에 적용하기 어려움
gRPC 를 지원하지 않는 문제는 해결할 방법이 있지만, Luft 워크로드를 멀티클라우드로 변경하는 것은 단기간에 실행하기 어려운 과제이므로 AWS Lambda 를 더 검토해보기로 했습니다. 자세한 내용은 실용적인 문제 해결방안에서 더 보겠습니다.
실용적인 문제 해결 방안
Luft 쿼리 옵티마이저
쿼리 옵티마이저로 해결하고자 하는 문제를 더 구체화해, 바로 적용해 의미있는 성능 개선을 얻을 수 있는 분기를 식별해봤습니다.
1.
특수한 대형 쿼리에 대한 스케일러 활용
2.
Cohort condition 분기
•
Cohort condition 쿼리와 집계 쿼리 동시 실행
◦
장점:
▪
두 쿼리를 병렬 실행 가능
▪
가능한 경우 두 쿼리를 하나로 합칠 수 있음
◦
단점:
▪
Cohort condition 대상이 아닌 유저의 데이터도 모으게 되므로, 리소스를 과다 사용함
•
Cohort condition 쿼리로 대상을 모은 후 그 대상에만 집계 쿼리 실행
◦
장점
▪
Cohort condition 대상인 유저의 데이터만 처리함
◦
단점
▪
두 쿼리를 병렬로 실행 불가
▪
Cohort condition 으로 필터되는 대상이 적은 경우, 불필요한 필터링만 중복으로 하게 됨
3.
AND 필터 분기
•
자식 필터 중 하나라도 실패하면 바로 실패
◦
장점: 빠른 실패 처리
◦
단점: 가능한 한 많은 이벤트를 한번에 필터하지 못 함
•
자식 필터 모두를 검사한 후 가장 많이 반복한 횟수를 활용해 실패
◦
장점: 가능한 한 많은 이벤트를 한번에 필터할 수 있음
◦
단점: 자식 필터 검사를 모두 수행해야 실패처리 할 수 있음
어떻게 해당 쿼리들을 구분할 수 있을지 고민해봅시다.
저는 크게 쿼리 결과를 활용하는 방법과, 메타 데이터 (테이블에 대한) 를 활용한 방법으로 구분해 보았습니다.
1.
특수한 쿼리를 스케일아웃해 처리
•
쿼리 결과
◦
쿼리 응답속도가 일정 값 이상
•
메타 데이터
◦
이벤트 수가 일정 값 이상
◦
유저 수가 일정 값 이상
2.
Cohort condition 분기
•
쿼리 결과
◦
Cohort condition 으로 수집된 유저가 일정 값 이상
•
메타 데이터
◦
특정 컬럼의 특정 값 (예: event category 의 click) 의 수가 일정 값 이상
3.
AND 필터 분기
•
쿼리 결과
◦
쿼리 응답속도
쿼리 결과를 활용하는 것보다 메타 데이터를 활용하는 것이 조금 더 일반적인 것으로 보이는데, Luft 에서는 상황에 따라 쿼리 결과를 활용하는 것이 더 효율적일 것으로 생각됩니다. 물론 모든 쿼리 조건과 실행계획에 대해 쿼리 결과를 활용하는 것은 불가능하므로, 적절한 절충안이 필요할 것입니다.
Luft 쿼리 옵티마이저 구현체
마지막으로 예상 구현체 목록을 정리하겠습니다.
1.
비용 데이터 수집기
•
메타 데이터와 쿼리 결과를 수집
•
비용 데이터
◦
메타 데이터
▪
이벤트 수
▪
유저 수
▪
컬럼 값 별 이벤트 수(미리 지정된 컬럼에 한해)
◦
쿼리 결과
▪
쿼리 조건에 따른 실행계획 별 응답속도
•
쿼리 조건은 적절한 해상도로 구분(예: 쿼리 기간이 1주일이면 같은 조건으로 판정)
•
모든 실행계획을 실행해 볼 수 없다는 것을 염두
•
프로비저닝만 되고 사용되지 않는 인스턴스를 수집기로 활용할 수 있을 것으로 기대
2.
실행계획 생성기
•
실행계획을 생성
•
실행계획은 매우 많아질 수 있음므로 모든 실행계획을 만드는 대신 휴리스틱한 규칙 사용이 필요함
•
예상 실행계획
◦
리소스 스케일러 사용 여부, cohort condition 대상 사전수집 여부, AND 필터 처리방식, etc
3.
실행계획 비용 계산기
•
쿼리 조건과 비용 데이터를 바탕으로 최적의 실행계획을 찾아냄
•
예상 쿼리 조건
◦
API 종류, 데이터 조회 기간, 필터의 형태, Group by 대상 컬럼의 수, etc
Luft 리소스 스케일러
Serverless 를 활요한 리소스 스케일러에 대한 아이디어는 오랫동안 있어왔지만, 구체적인 구현은 아직 시작하지 못했습니다. 이번에 AWS Lambda 를 검토하며 가시성을 좀 더 높여보았는데 이를 함께 살펴봅시다.
먼저 일반적인 Luft 워크로드를 살펴보겠습니다.
1.
Scan data from persistence: 디스크 등의 퍼시스턴스 계층에서 데이터를 읽고
2.
Group by user: 유저 별로 이벤트를 모은 후
3.
Computing: 개별 쿼리를 위해 필요한 연산을 수행합니다.
•
추가로 네트워크 I/O, GC 등 특정 단계에 포함되지 않는 부분(ETC) 이 있습니다.
아래는 이 워크로드에 대한 CPU 사용량 Flamegraph 입니다.
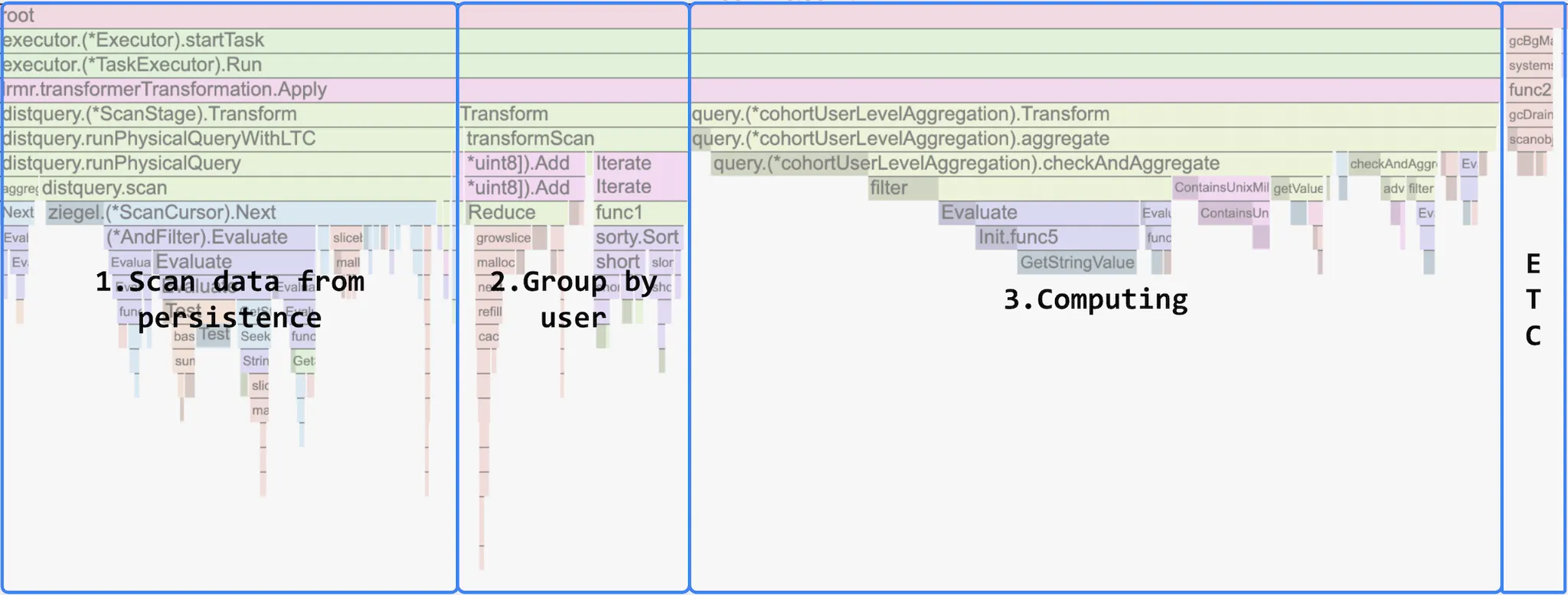
AWS Lambda 를 활용가능성을 확인하기 위해 아래와 같은 작업을 했습니다.
1.
Computing 구현체를 Lambda 에서 실행가능한 형태로 재구성
2.
Lambda 호출(HTTP or invoke with SDK)
3.
Lambda 에서 gRPC(TCP outbound) 를 통해 Luft cluster 에 연결
4.
쿼리 처리
Lambda 가 gRPC 를 지원하지 않기 때문에 부수적인 작업이 약간 있었지만, 처리가 가능함을 확인했고 결과는 아래와 같습니다.
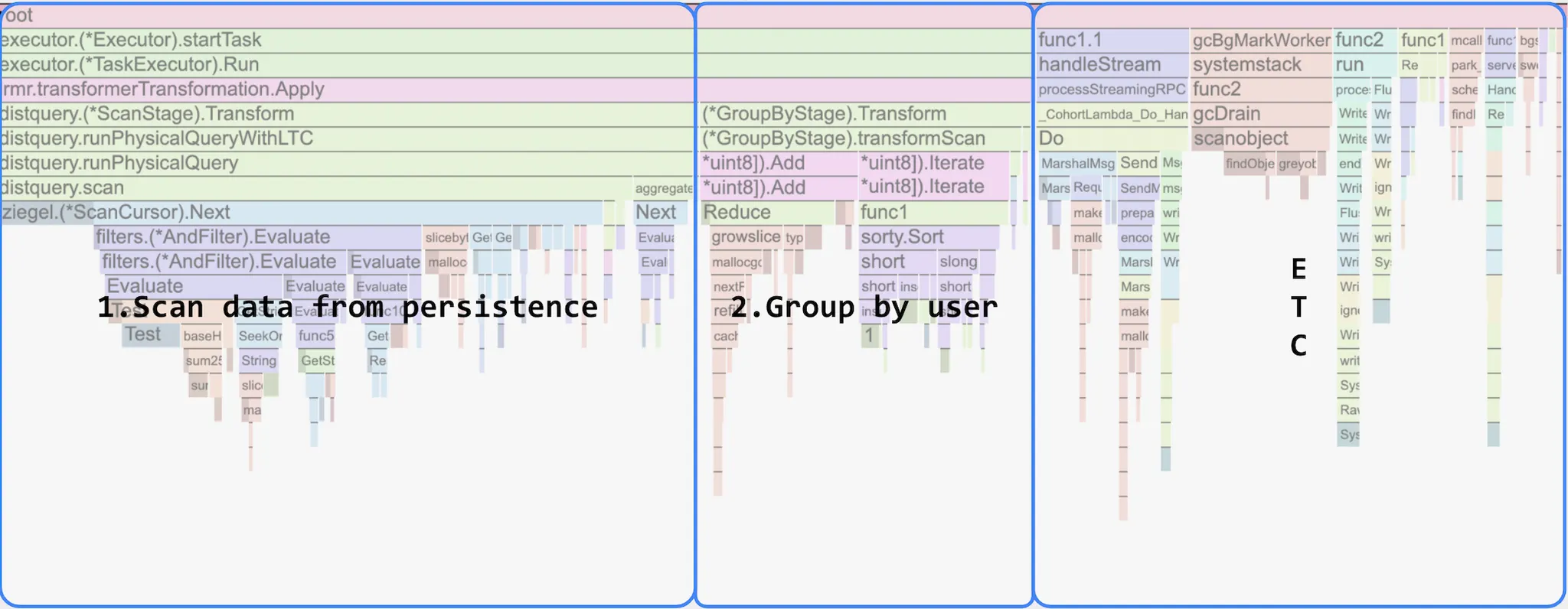
Computing 부분은 완전히 제거되고 네트워킹 처리, GC 등과 부수적인 작업을 위한 ETC 부분이 늘어난 것을 확인할 수 있습니다. 또 쿼리 수행시간은 1.65 초 (10.82 초 → 9.17 초) 줄었습니다.
이 실험에서 성능 향상이 크지는 않았지만, 최적화되지 않은 코드를 활용해 쿼리 스테이지의 일부만 Lambda 로 옮겼음에도 전체 쿼리 수행시간을 줄일 수 있다는 것은 흥미로운 결과입니다. 이론적으로 첫 번째 스테이지 외에는 쉽게 Lambda 로 워크로드를 옮길 수 있으므로, 아래 두 가지 문제를 해결할 수 있을 것으로 기대합니다.
1.
컴퓨팅 자원 부족
2.
디스크 사용에 (메모리 부족으로 유발되는) 따른 급격한 성능 감소
Luft 리소스 스케일러 구현체
마지막으로 예상되는 구현체를 정리해보겠습니다.
1.
Luft 맵리듀스 계층이 미리 등록되지 않은 리소스를 사용할 수 있게 개선
2.
AWS Lambda 를 리소스로 등록
•
Serverless 사용으로 비용 효율이 나오는 지점을 정밀하게 측정해야 함
마치며
해결하고자 했던 문제를 다시 한 번 정리해 보겠습니다.:
1.
스케일링을 덜 휴리스틱한 방법으로 하고 싶다.
•
달성 가능
2.
오버 프로비저닝 하고 싶지 않다.
•
달성 가능
•
Serverless 비용이 미리 프로비저닝한 인스턴스보다 저렴한 것을 추가로 증명해야 함
3.
특정 쿼리에만 적용되는 최적화를 적용하고 싶다.
•
달성 가능
아쉬운 부분도 있지만 해결하고자 했던 문제에 대한 가시성이 꽤 높아진 것 같습니다. 어떠신가요? 여러분도 제가 꾼 달콤한 꿈을 함께 꾸셨나요? 이를 실현시킨 모습을 가까운 미래에 여러분께 다시 공유드리길 기대하며 로드맵과 함께 제안서를 마치겠습니다.
로드맵
•
2023 년 4 분기
1.
쿼리 옵티마이저 구현체에 대한 구체적인 디자인
2.
비용 데이터 수집기
•
2024 년 1분기
3.
실행계획 생성기
4.
실행계획 비용 계산기
•
2024 년
1.
리소스 스케일러 구현체에 대한 구체적인 디자인
2.
맵리듀스 계층이 미리 등록되지 않은 리소스를 사용할 수 있게 개선
3.
AWS Lambda 를 리소스로 등록
ᴡʀɪᴛᴇʀ

