

상황을 고려한 엔지니어링으로 검색 속도 개선하기
Wonbin Ha — 하원빈
@wonbin
문제의 인식
트래킹링크는 유저가 발생시킨 데이터를 수집하는 에어브릿지의 핵심 기능입니다. 대시보드에서는 매일 약 10만개씩 생성되는 트래킹링크에 대해서 조회 및 검색 기능을 제공하고 있습니다.
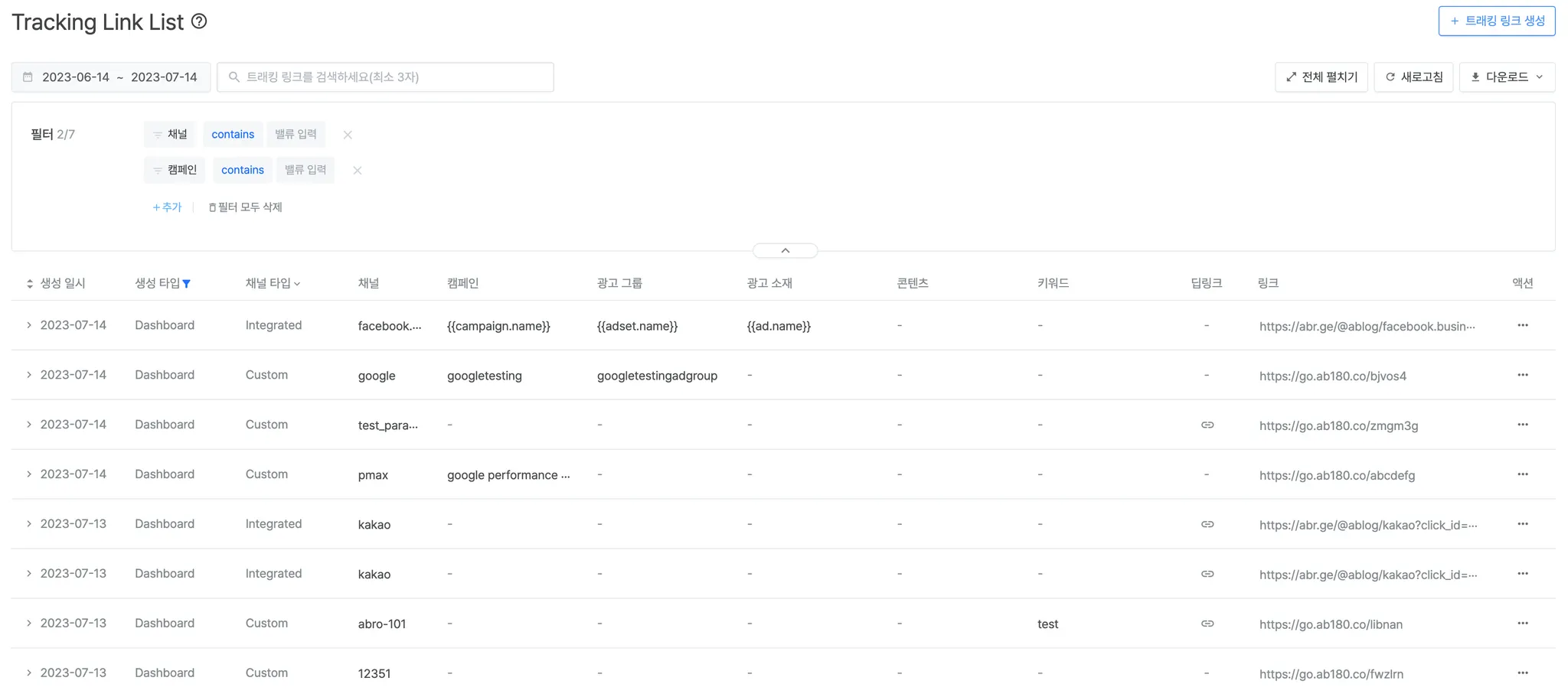
처음 만들었을 때는 빠르고 간결한 시스템이었지만 트래킹 링크 데이터는 모든 내용을 영구적으로 저장하고 있기 때문에 데이터가 쌓이면 쌓일수록 점점 검색 성능이 떨어졌고, 결국 검색 소요 시간이 분 단위로 늘어나 사용자 경험에 영향을 주었습니다. 이를 해결하기 위해 검색에 사용하고 있는 SQL 쿼리를 확인해 보았습니다.
실제로 확인해본 검색 쿼리에는 두가지 문제점이 있었습니다. 실제 작업했던 내용은 도서 검색 시스템을 예시로 들어 설명하겠습니다.
CREATE TABLE tbl_books
(
id INT PRIMARY KEY NOT NULL,
title VARCHAR(128) NOT NULL,
author_id INT NOT NULL,
publisher_id INT NOT NULL,
published_at DATETIME DEFAULT CURRENT_TIMESTAMP NOT NULL,
CONSTRAINT _tbl_books_author_fk
FOREIGN KEY (author_id) REFERENCES tbl_authors (id)
CONSTRAINT _tbl_books_publisher_fk
FOREIGN KEY (publisher_id) REFERENCES tbl_publishers (id)
);
SQL
복사
tbl_books 의 DDL
1.
Text Column에 대한 복잡한 LIKE Query.
•
검색을 해야하는 컬럼은 길이가 최소 100자 이상의 텍스트입니다. 텍스트 전체에 대해서 LIKE Query를 하고 있기 때문에 성능이 좋지 않았습니다.
•
검색하기 위해서는 다음과 같이 정규식을 사용하고 있어서 가시성도 떨어지고 성능도 좋지 않았습니다.
•
해당 도서의 이미지의 경로의 특정 키워드를 검색하기 위해서 아래와 같은 쿼리를 사용하고 있었습니다.
tbl_book_detail.image_path REGEXP '([^/]*keyword[^/]*\.jpg)$'
SQL
복사
2.
많은 테이블들간의 Join
•
생성한 유저 정보도 함께 조회를 하기 때문에 다른 테이블간의 Join이 많았습니다.
•
생성한 유저의 email에 대한 검색 기능이 제공되기 때문에 기존테이블과 Join 된 테이블 모두 LIKE Query가 필요한 경우도 있었습니다.
두 문제 모두 검색 시 데이터를 Full Scan을 하고 있어서 생기는 것으로 단순히 쿼리 전략을 수정하는 것이 아닌 근본적인 해결책이 필요했습니다.
문제 해결 전략
검색용 테이블 생성
검색 시스템을 생각하면 제일 먼저 보통 Elasticsearch를 떠올립니다. 이번 문제를 해결하기 위해서 Elasticsearch를 고려하였지만, Main DB로 사용하고 있는 AuroraDB에서 발생하는 변경사항들을 실시간으로 동기를 맞추기 어려워서 오히려 기능의 중요도나 개선을 통해 고객이 느끼는 가치보다 시스템을 구축하고 운용하는 데 드는 비용이 필요 이상이라고 판단하였습니다. 많은 양의 영구 데이터를 안정적으로 운영하려면 그에 상응하는 노력이 필요하다고 생각했고, 우선은 고객이 조회를 못 하는 상황에서 합리적인 시간 내에 조회를 가능하게 만드는 것을 최우선 목표로 합의했습니다. 그래서 새로운 시스템을 도입하기보단 기존 DB에 검색용 테이블을 생성하는 방식으로 리서치를 시작했습니다.
1.
역직렬화 테이블
처음에는 역직렬화 된 테이블을 생각했습니다. 검색 키워드들을 index로 삼아서 id를 연결해주는 테이블을 만들어서 검색을 한 후 결과를 조회하는 방식이었습니다.
keyword,book_id
'개발자',[1, 2, 3, 4]
'성장',[1, 2, 3, 5, 6]
'파이썬',[6, 8, 9]
SQL
복사
keyword에 index를 걸어두고 도서의 reference id를 찾아서 반환하는 구조였습니다. 하지만 이 방식은 검색 키워드가 많을 경우 하나의 책에 대해서 수십개의 Row가 추가되어야 하므로 생성 성능을 저하시키기 때문에 사용할 수 없었습니다.
2.
검색 테이블 단순화
최종적으로 모든 필드를 컬럼으로 만들어서 인덱스를 생성하는 방법을 선택하였습니다. 검색용 테이블에는 검색과 조회에 필요한 값들을 모두 저장하여 2번 문제인 많은 테이블과의 Join을 최소화하고자 하였습니다. 또한 정규식을 사용하지 않고 특정 컬럼에 대해 바로 검색할 수 있습니다.
CREATE TABLE tbl_book_detail_search
(
book_id INT PRIMARY KEY NOT NULL,
title VARCHAR(128) NOT NULL,
author VARCHAR(128) NOT NULL,
publisher VARCHAR(128) NOT NULL,
edition VARCHAR(128) NULL,
language VARCHAR(128) NULL,
genre VARCHAR(128) NULL,
sub_genre VARCHAR(128) NULL,
cover_type VARCHAR(128) NULL,
image_path VARCHAR(128) NULL,
location_in_library VARCHAR(128) NULL,
published_at datetime DEFAULT CURRENT_TIMESTAMP NOT NULL,
CONSTRAINT _tbl_book_detail_fk
FOREIGN KEY (book_id) REFERENCES tbl_books (id)
);
SQL
복사
도서 검색을 예시로 든 검색을 위한 테이블
조회 성능향상을 위해 모든 컬럼에 대해 인덱스를 걸어주었습니다. 그러나 인덱스의 총 길이가 제한되어 있으므로 varchar 타입의 컬럼은 길이를 제한해야 했습니다. 대체로 각각의 컬럼들은 50자를 넘기는 경우가 드물기 때문에 50자로 기준을 정하였습니다. 필수적인 조건의 경우에는 인덱스의 앞쪽에 위치하도록 하였습니다.
CREATE INDEX tbl_book_detail_search_index
ON tbl_book_detail_search (published_at, title(50), author(50), publisher(50), edition(50), language(50), genre(50), sub_genre(50), cover_type(50), image_path(50), location_in_library(50));
SQL
복사
도서 검색용 테이블의 인덱스
쿼리는 다음과 같이 변경되었습니다. 여러 테이블을 Join하는 문제는 검색용 테이블 하나만 Join 하도록, 정규식을 사용하는 문제는 Like를 사용하도록 개선하였습니다.
SELECT * FROM
tbl_book_detail
INNER JOIN tbl_book_detail_search
ON tbl_book.id = tbl_book_detail_search.book_id AND
(LOWER(tbl_book_detail_search.title) LIKE LOWER('%value%') OR
LOWER(tbl_book_detail_search.author) LIKE LOWER('%value%') OR
LOWER(tbl_book_detail_search.publisher) LIKE LOWER('%value%') OR
LOWER(tbl_book_detail_search.edition) LIKE LOWER('%value%') OR
LOWER(tbl_book_detail_search.language) LIKE LOWER('%value%') OR
LOWER(tbl_book_detail_search.genre) LIKE LOWER('%value%') OR
LOWER(tbl_book_detail_search.sub_genre) LIKE LOWER('%value%') OR
LOWER(tbl_book_detail_search.cover_type) LIKE LOWER('%value%') OR
LOWER(tbl_book_detail_search.image_path) LIKE LOWER('%value%') OR
LOWER(tbl_book_detail_search.location_in_library) LIKE LOWER('%value%')) AND
tbl_book_detail_search.published_at BETWEEN '2021-01-01' AND '2023-01-01' AND
ORDER BY
tbl_book_detail.id DESC
SQL
복사
도서 검색 쿼리 중 일부
데이터 적재
검색용 테이블을 이용하기 위해서는 검색용 테이블에 데이터를 적재해 주어야 합니다. 여기서 중요한 것은 어떻게 생성 로직의 성능에 최대한 영향을 주지 않고 하나의 트랜잭션 안에서 데이터를 쌓아줄 것 인가입니다. 별도의 장치 없이 한 트랜잭션 내에서 트래킹링크를 생성할 때 기존 테이블과 검색용 테이블에 데이터를 함께 적재하도록 로직을 구현했을 때는 생성 속도가 기존에 비해서 20% 나 저하되었습니다.
데이터를 적재하는 방법으로는 다음과 같은 방법들이 있었습니다.
1.
Queue를 통해서 별도의 워커가 데이터를 처리하는 방법
•
장점
◦
UPDATE, DELETE를 워커가 처리하므로 SQL보다 유연한 방식으로 처리가 가능합니다.
◦
거의 동기적으로 처리하는게 가능합니다.
•
단점
◦
워커 개발을 위한 추가 리소스가 필요합니다.
AWS SQS 로 데이터를 전송하여 외부 컴포넌트(워커)에서 INSERT, UPDATE, DELETE를 구분하여 처리할 수 있습니다. 단순한 처리를 하므로 빠른 속도로 동작할 수 있어서 어느 정도 시간차는 있지만 거의 실시간으로 데이터를 적재할 수 있습니다. 그러나 새롭게 워커를 만들어야 하고 이는 또 다른 관리 포인트가 되기에 다른 접근 방식을 취하고자 했습니다.
2.
Batch Job을 이용한 동기화
•
장점
◦
생성 로직에는 영향이 가지 않습니다.
•
단점
◦
데이터 동기화에 어느 정도 시간이 소요됩니다.
◦
UPDATE 나 DELETE 에 대한 변경 감지가 쉽지않습니다.
주기적으로 테이블을 검사하여 변화를 감지하여 추가하는 방식이 있습니다. 기존 생성 로직을 수정하지 않고도 데이터를 적재할 수 있다는 장점은 있지만 일정 시간마다 동기화 처리를 하므로 최악의 경우 주기의 2배 동안 정합성이 맞지 않을 수 있습니다. 이는 사용자가 검색 및 조회 기능을 사용하는데 매우 좋지 않은 경험을 주리라 판단하였습니다. 또한 데이터의 UPDATE나 DELETE의 추적이 어렵다는 단점도 존재했습니다.
3.
MySQL Trigger
•
장점
◦
생성 로직에 영향 없이 사용할 수 있습니다.
◦
다른방법에 비해서 빠르게 작업을 할 수 있습니다.
•
단점
◦
삭제와 생성으로 트리거를 수정해야하므로 삭제와 생성 사이에 딜레이가 생길 수 있습니다.
이 중에서 추가적인 컴포넌트 생성과 코드로 관리할 필요가 없는 MySQL의 Trigger 기능을 이용하기로 하였습니다. Trigger는 설정을 해두면 동작을 항상 감시하고 있다가 조건에 해당하는 동작이 수행되는 순간 실행되는 특징을 가지고 있습니다. 기존의 생성 로직을 수정하지 않고도 하나의 트랜잭션으로 동작할 수 있다는 장점이 있습니다. 또한, 실제로 생성 테스트 시에도 다른 방법들에 비해 가장 적은 성능 저하를 보였고, 이는 수용 가능한 정도라고 판단했습니다. 또한 개발 공수 등 추가 리소스가 가장 적게 들므로 빠르게 작업할 수 있었습니다.
CREATE TRIGGER after_insert_tbl_book_trigger
--- 조건 ---
AFTER INSERT
ON tbl_book
FOR EACH ROW
BEGIN
--- 실제로 수행하고자 하는 것 ---
END
SQL
복사
위와 같은 SQL 문 한 번으로 간단하게 해결할 수 있다는 장점은 있었지만, 트리거의 수정작업이 필요할 때, 트리거를 삭제 후 다시 생성해 줘야 하므로 트리거의 삭제와 재생성 사이에 놓쳐지는 데이터가 생길 수 있습니다. 이는 Airflow 같은 스케쥴러를 통해서 누락된 데이터를 다시 적재하도록 했습니다. 한 트랜잭션으로 동작하기 때문에 Trigger 동작에서 에러가 발생하게 된다면 기존의 INSERT 동작도 실패하기에 원본 테이블에는 존재하지만, 검색용 테이블에는 존재하지 않아 정합성이 지켜지지 않는 상황을 줄였습니다.
성과
위의 문제해결 전략처럼 검색용 테이블을 새로 만들고 인덱스를 새로 구성하는 것만으로도 많은 성능 개선이 되었습니다. 실제로 고객사에서 에러를 경험했던 케이스에 대해서는 3분 이상 소요되던 쿼리가 약 2초 만에 결과가 나타났습니다. 트래킹링크 리스트에 대한 다운로드 기능도 유사한 로직을 갖고 있기 때문에 동시에 성능을 향상시킬 수 있었습니다. 그리고 기존에 발생하던 슬로우 쿼리 알람도 울리지 않게 되었습니다.
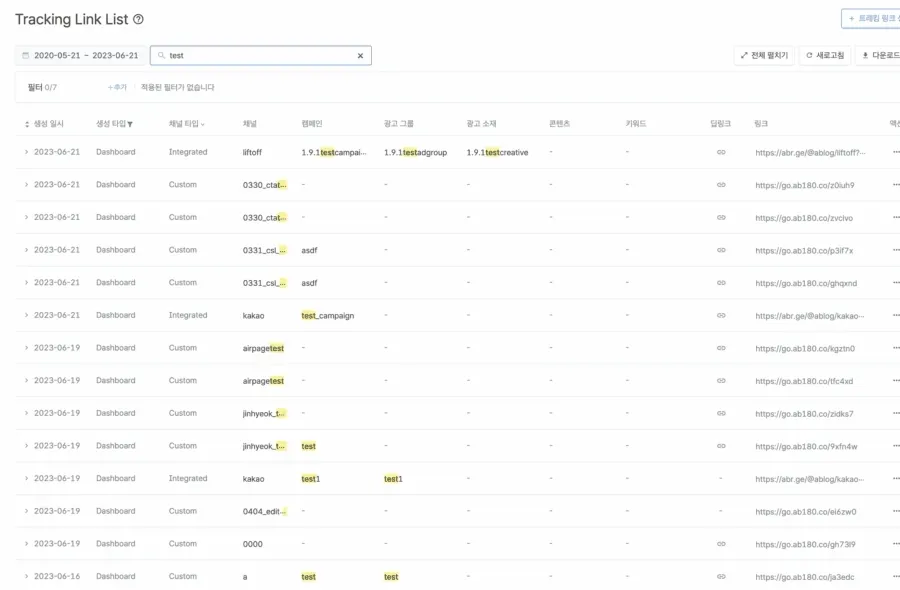
개선 전
.gif&blockId=27a45de1-e04a-4634-bbb8-ddb58bdce170)
개선 후
마치며
이번 개선작업을 하면서 다른 개발자분들께 여러 가지 접근 방법에 대한 조언을 얻을 수 있었는데 특히 MySQL Trigger에 대해서 전혀 고려하지 못했으나 조언 덕분에 실험해 보고 적용해 볼 수 있었습니다. 또한 직접 많은 데이터에 대해서 가공해 보고 시도해 보면서 RDB의 동작 방식에 대해서 좀 더 깊이 알 수 있었습니다. 개선에 대한 성과도 있었지만, 현재 주어진 환경에서 문제를 인식하고, 여러 해결 방법 중에 어떤 방법이 더 최선일까 고민하고 선택해 보는 과정에서 적절한 엔지니어링이란 어떤 것인지 생각해 보게 되었습니다. 서비스의 규모가 한 번 더 폭발적으로 성장한다면 지금의 방법으로 해결하지 못할 수도 있습니다. 그날이 온다면 다른 적절한 방법으로 문제를 해결한 이야기를 들려드릴 수 있도록 하겠습니다.
ᴡʀɪᴛᴇʀ
Wonbin Ha @wonbin
Platform Engineer @AB180

