

Intro
모니터링을 위해 Log를 잘 수집하고 볼 수 있게 만드는 것의 중요성은 모두가 동감할 것입니다. 문제가 생겼을 때 볼 수 있는 것은 Log와 metric뿐이기 때문입니다. 그래서 시중에는 다양한 솔루션들이 존재합니다. AWS에서는 CloudWatch 서비스 아래에서 metrics와 logs를 제공하는데, AWS 내 다른 서비스들과 깊게 관련되어 있습니다.
CloudWatch에서 metrics는 많이들 쓰실 텐데 AWS 내 다른 서비스들의 metric을 기본적으로 CloudWatch metrics로 제공하고 있고, 그 metrics를 대상으로 Alarm을 설정하는 경우가 많습니다. 반면, logs는 좀 더 사용하기 까다롭습니다. EC2 환경에서 서비스를 운영하는 분들이 많은데, EC2에서 CloudWatch Logs로 log를 shipping 하기 위해서는 CloudWatch Logs Agent를 설치해야 하기 때문입니다. 이 과정에서 어차피 agent를 설치하고 운영해야 하다 보니 아예 ELK stack을 운영하는 분들도 있습니다.
Airbridge Log 운영 환경
Airbridge는 그 자체로 데이터를 수집, 처리, 제공하는 서비스다 보니 고객의 log가 있고, 서비스 운영 과정에서 생성되는 application server의 log가 있습니다. 여기서 application server의 log는 CloudWatch Logs로 수집, 관리, 조회하고 있습니다.
이런 운영 환경을 가지는 가장 큰 이유는 application server 들을 ECS와 Lambda에서 대부분 운영하고 있기 때문입니다. ECS와 Lambda에서 application을 실행할 경우, stdout, stderr의 log가 자동으로 CloudWatch Logs와 연동되기 때문에 특별한 설정 없이 CloudWatch Logs에서 log를 볼 수 있다는 장점이 있습니다.
저는 Log가 여러 곳에 흩어져있으면 좋지 않다고 생각합니다. 데이터가 파편화 되어 있다 보니 어떤 log를 어디서 봐야 하는지 고민해야 하는 것부터가 문제라고 생각하기 때문입니다. 여러 솔루션으로 Log를 관리하면 관리 비용도 더 커집니다. 특히, ELK stack과 같은 것을 직접 운영하면 생각보다 신경 써야 할 점들이 많습니다. 예를 들어, Logstash가 중요한 중간 저장소 역할을 해서 모니터링을 잘 해야 합니다.
그러므로, application server뿐만 아니라 다른 Infra 들의 log도 CloudWatch Logs에서 모아보기로 했고, 다른 Infrastructure instance 들에도 CloudWatch Logs Agent를 설치하여 CloudWatch Logs에서 함께 볼 수 있게 구성했습니다.
CloudWatch Logs의 아쉬운 점
그렇다고 해서 CloudWatch Logs가 만능 솔루션은 아닙니다. CloudWatch Logs를 사용하다 보면 크고 작은 아쉬운 점들이 분명히 있습니다.
대표적으로 log 검색이 불편하다는 문제가 있습니다. 기본적인 log 탐색 패턴은 log group을 찾아 들어가서 “Search log group” 버튼을 클릭한 뒤 키워드를 넣어서 log를 찾아보는 것입니다. 그런데, 여기서 검색할 때는 log 내 특정 field에 대한 검색이 아니라 전체 log text에 대한 검색만 가능합니다.
Logs Insights 활용
이 부분을 해결하기 위해 CloudWatch Logs Insights를 활용할 수 있습니다. Log를 JSON format으로 남기면 아래와 같이 JSON 아래 특정 field로 검색을 할 수 있어서 유용합니다.
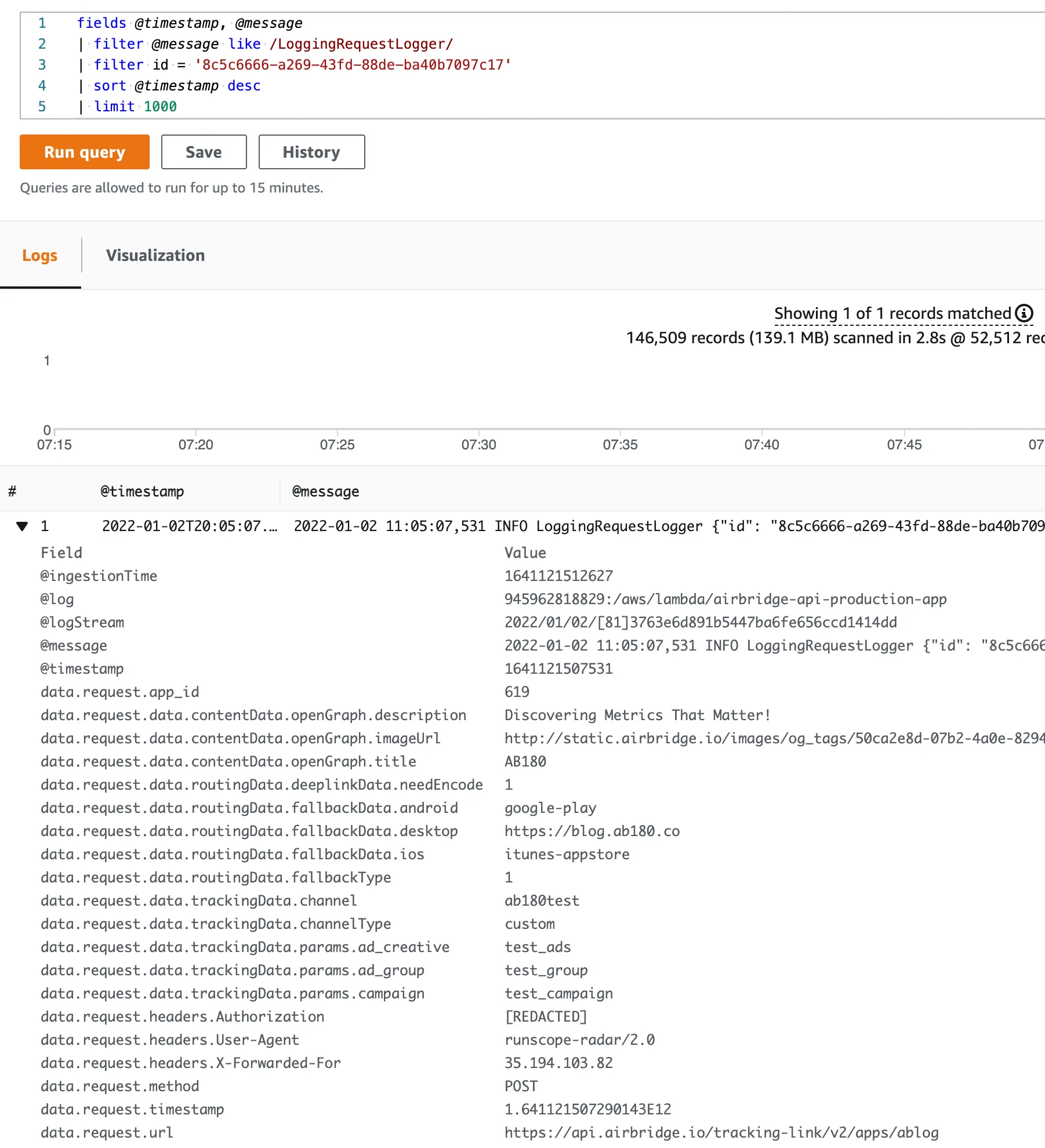
그러나 Insights에서도 아래와 같은 아쉬운 점들이 있습니다.
•
최대 1000개 row까지만 조회할 수 있습니다. 꽤 많은 데이터를 찾아보고 싶은 경우, 이 제한 때문에 불편함이 상당합니다.
•
데이터가 느리게 나타납니다. 체감상 몇 분 정도는 기다려야 나타나는 것 같은데, 정확한 시간은 측정해보지 않았습니다. 그래서 배포 후 즉시 Log를 보고 싶은 경우에는 적합하지 않습니다.
•
지원하는 함수들이 적습니다. 예를 들면, 날짜와 시간과 관련된 함수 지원이 미흡합니다. 문자열과 관련된 함수도 몇 개 있긴 하지만 실제로 query 할 때는 불편한 점이 많습니다. 어떤 함수들이 지원되는지는 문서를 참고 부탁드립니다.
•
문법이 SQL과 상당히 다릅니다. 단순 조회뿐만 아니라 OLAP 데이터 조회의 경우도 그런데, CloudWatch Logs Insights에서는 SQL의 group by query와 같은 데이터를 조회하기 위해 상당히 다른 query를 작성해야 합니다. 이 과정에서 생산성 저하를 크게 느낀 적이 많습니다. 제가 SQL을 너무 좋아해서 그런 것인지 모르겠으나, 거의 모든 종류의 데이터를 조회할 때 SQL이 가장 편리하다고 확신합니다.
다른 DB의 데이터를 합쳐서 보고 싶은 경우
Log를 조회하다 보면 DB의 데이터를 함께 보고 싶은 경우가 자주 생깁니다. 보통 log에는 완벽하게 데이터를 남기지 않는 경우가 많습니다. 완벽하게 데이터를 남기려면 꽤 많은 양의 데이터를 남겨야 하기도 하고, 나중에 어떤 데이터를 찾아보게 될지 예상하기 어렵기 때문입니다.
DB에는 모든 데이터를 저장하는 경우가 많아서 log를 DB의 데이터와 합쳐서 보고 싶은 경우가 자주 생깁니다. 단건에 대해 찾아볼 때는 괜찮지만 여러 건을 찾아봐야 할 때는 상당히 피곤한 노가다가 됩니다. 저의 경험으로는 CloudWatch Logs Insights에서 원하는 field 들을 CSV로 export하고, 이 CSV를 약간 가공해서 SQL을 만든 뒤, DB에서 query를 한 경험이 있습니다. 이 과정이 가능은 하지만 굉장히 불편합니다. 특히, field 내에 double quote 기호(")가 포함되면 CSV format 특성상 처리하기 더 불편해집니다.
DB에 익숙한 사람이라면 join을 잘 활용할 수 있다는 것을 알 테지만, log가 DB에 남는 것이 아니기 때문에 DB에서 query로 처리하려면 DB에 필요한 데이터를 import 하여 query에서 사용하는 과정이 필요합니다. 이렇게 되면 쓰기 권한이 필요해지므로 데이터를 보려는 사람의 권한 문제까지 생길 수 있습니다.
방향성 결정
위 문제들을 해결하는 새로운 방법에서 반드시 되어야 하는 것은 아래 2가지라고 생각했습니다.
•
SQL을 쓸 수 있어야 합니다. Airbridge에서는 New Relic이라는 모니터링 도구 또한 쓰고 있는데, New Relic에서도 SQL로 데이터를 볼 수 있게 지원합니다. NRQL이라는 다소 특이한 문법을 가진 query 언어이지만 SQL과 유사해서 팀 내 사용자 경험이 좋았습니다.
•
다른 DB의 데이터를 합쳐서 볼 수 있어야 합니다. 그 과정이 조금 불편하더라도 가능은 해야 나중에 데이터 기반 의사 결정을 해야 할 때 데이터를 온전히 보고 판단할 수 있습니다.
위 2가지 문제는 Athena로 query를 할 수 있게 만들면 해결할 수 있겠다고 결론 내렸습니다.
Athena Federated Query 시도
AWS에서는 S3 데이터를 query 할 때 Athena를 활용하는 것을 추천합니다. Athena가 serverless고, S3 또한 serverless 이므로 꽤 편리하게 사용할 수 있습니다. 2019년, Athena의 장점을 살려 S3뿐만 아니라 다른 Data source 들도 query 할 수 있게 만드는 Federated Query라는 기능을 처음 소개했습니다.
Federated Query에서는 DynamoDB나 Elasticsearch, JDBC, CloudWatch connector 등을 제공합니다. 여기서 CloudWatch connector를 활용하면 지금 겪고 있는 문제를 해결할 수 있을 것 같아 시도했습니다. 결론을 먼저 말하자면 이 방법은 쓰지 않기로 했습니다.
CloudWatch connector 사용
CloudWatch connector 문서에서 Federated Query를 사용하기 위해 어떻게 배포하면 되는지와 사용 방법을 확인할 수 있습니다. 큰 골자를 보면 아래와 같습니다.
1.
CloudWatch log를 검색해주는 Lambda 배포
2.
Athena에서 query 할 때 1에서 배포한 Lambda를 호출하여 CloudWatch의 데이터 로드
그러나 실제로 배포 후 사용해봤을 때는 두 가지 문제점을 겪고 포기하기로 했습니다.
•
Query가 매우 오래 걸립니다. 특정 log stream에 대한 query도 몇십 초 이상 걸렸고, 전체 log stream(all_log_stream)에 대해 query 할 때도 마찬가지였습니다.
•
모종의 에러가 발생했습니다. 간단하게 검색했을 때는 원인을 찾기 쉽지 않았습니다. 그러나, 여기서도 마찬가지로 150초 이상 기다린 뒤에야 에러가 발생했습니다.
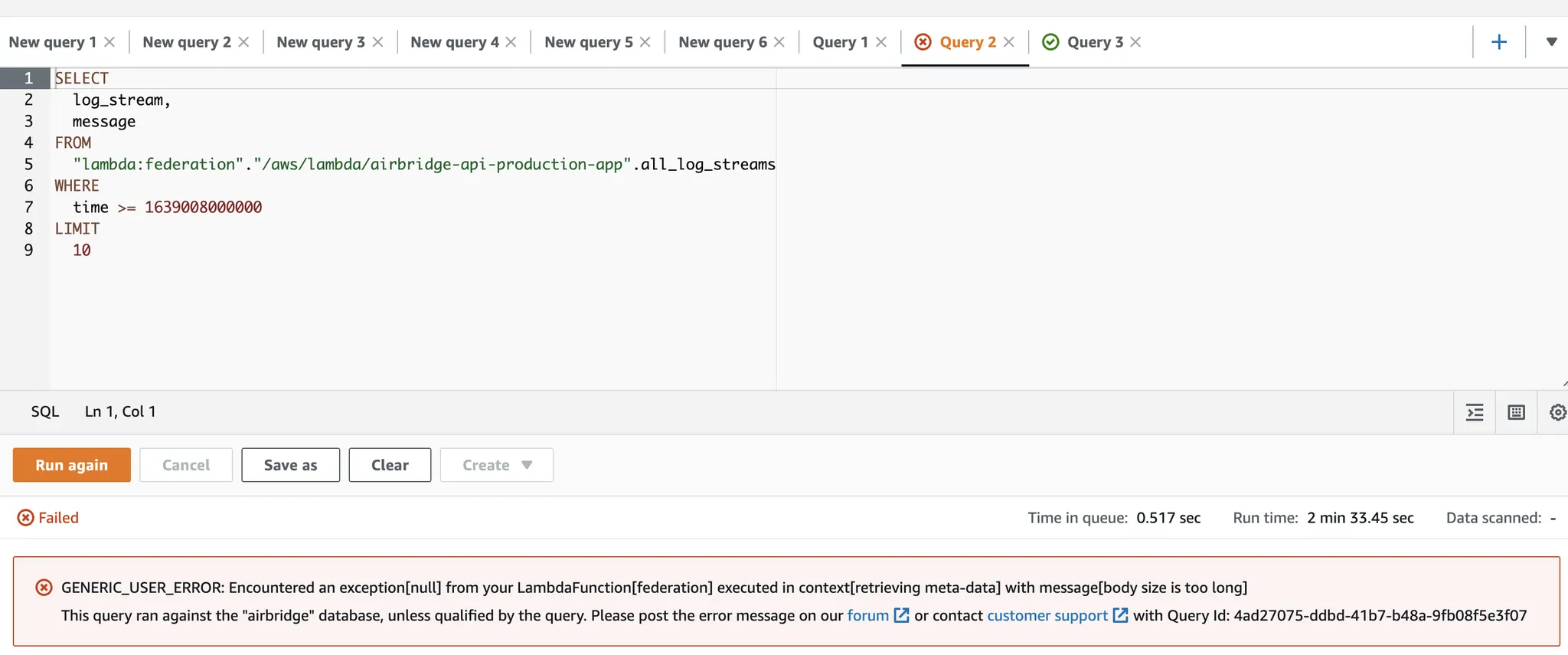
Query 성공, 실패 모두 시간이 오래 걸리는 것은 앞으로도 생산성에 좋지 않을 것 같아 빠르게 포기하고 다른 방법을 시도하기로 했습니다. 하지만 추가 연동 없이 앞으로도 잘 활용할 수 있는 방법이라면 활용성이 높을 것 같아 아쉬움이 많이 남습니다. 추후 시간과 기회가 된다면 좀 더 방법을 찾아보려고 합니다.
Log를 S3로 Shipping하고 Athena로 query
CloudWatch Logs의 subscription filter와 Kinesis Firehose를 활용하면 S3로 log 들을 shipping 할 수 있고, S3에 데이터가 저장되기만 하면 Athena를 활용할 수 있습니다.
1.
CloudWatch Logs subscription filter로 Firehose에 log event 들을 보낼 수 있습니다.
2.
Log event는 약간의 가공이 필요합니다.
•
gzip 압축 해제를 해줘야 하고, 황당하지만 log 문자열 끝에 개행문자를 추가해줘야 Athena에서 각 log 별로 row를 인식할 수 있습니다.
•
3.
Kinesis Firehose에서 Data Transform 기능으로 2에서 배포한 Lambda를 호출합니다.
4.
S3 unloading 설정대로 S3에 데이터가 저장됩니다.
연동 방법은 이미 자료가 너무 많으므로 여기서는 어떤 고려 사항과 주의 사항들이 있을지 위주로 살펴보겠습니다.
고려했던 사항들
아래 사항들을 생각해볼 수 있습니다.
•
Log group과 Firehose를 1:1로 만들 것인지, N:1로 만들 것인지
◦
여러 Log group에서 하나의 Firehose를 호출하도록 subscription filter를 추가할 수 있습니다. 그래서, Firehose는 하나만 생성하고, 여러 Log group이 하나의 Firehose를 호출하도록 할 수도 있습니다.
◦
Firehose에는 Dynamic Partitioning 기능이 있어서 log에 log group을 잘 남겨주도록 Data Transform에서 처리를 해주면 firehose 하나로도 S3에 partitioning 하여 데이터를 남기게 할 수 있습니다.
◦
대신, Firehose의 dynamic partitioning 기능 관련 몇 가지 제한 사항들을 잘 고려해야 합니다.
▪
예를 들면, 최대 partition 개수 제한이 있습니다.
•
Partition projection
◦
S3의 데이터를 Athena에서 query 할 수 있게 하려면 Athena에서 external table을 생성해야 합니다.
◦
Athena에서 table을 만들 때 partitioned table로 생성하면 query에서 읽는 데이터의 양을 줄이고 속도도 개선할 수 있습니다. Partitioned table은 S3에 데이터를 partitioning 해서 남기도록 해야만 사용할 수 있습니다. 이를 위해 Firehose에서 S3 prefix를 잘 지정해줘야 합니다.
◦
Athena partitioned table 관련 자료를 찾았을 때 대부분 MSCK REPAIR TABLE query로 partition을 인식하는 방법을 소개하는데, 저는 Partition Projection 기능을 강력하게 추천합니다. 아래 query는 partition projection 기능을 활용한 DDL 예시입니다.
CREATE EXTERNAL TABLE `airbridge_api_request_logs`(
`request_ts` string COMMENT '',
`log_level` string COMMENT '',
`class_name` string COMMENT '',
`payload` string COMMENT '')
PARTITIONED BY (
`log_group` string COMMENT '',
`sink_date` string COMMENT '')
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'input.regex'='(\\d+-\\d+-\\d+\\s\\d+:\\d+:\\d+,\\d+) ([^ ]*) ([^ ]*) (.*)')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://airbridge-logs/'
TBLPROPERTIES (
'classification'='csv',
'compressionType'='none',
'projection.enabled'='true',
'projection.log_group.type'='enum',
'projection.log_group.values'='.aws.lambda.airbridge-api-production-app,.aws.lambda.airbridge-api-development-app,.aws.lambda.airbridge-dashboard-production-app,.aws.lambda.airbridge-dashboard-development-app',
'projection.sink_date.format'='yyyy-MM-dd',
'projection.sink_date.interval'='1',
'projection.sink_date.interval.unit'='DAYS',
'projection.sink_date.range'='NOW-5YEARS,NOW',
'projection.sink_date.type'='date',
'storage.location.template'='s3://airbridge-logs/cwlogs-to-s3/${log_group}/success/date=${sink_date}/',
'typeOfData'='file')
SQL
복사
▪
storage.location.template 속성의 변수 부분을 projection.변수명 으로 어떻게 인식하면 될지 정의할 수 있습니다.
▪
위와 같이 정의해두면 날짜별로 추가되는 partition을 인식하기 위해 MSCK REPAIR TABLE query를 실행하지 않아도 됩니다.
•
Firehose buffer size & interval
◦
Firehose가 S3에 얼마나 자주 데이터를 남기게 할 것인지 buffer size와 interval을 설정할 수 있습니다.
◦
대부분의 경우 size와 interval을 늘릴수록 S3 비용, Athena query 비용이 줄어들지만, 실시간성이 떨어집니다.
◦
개인적으로 근거는 없지만 5분 rule이 적당하다고 생각합니다. 대용량 환경에서 5~10분 정도 내에 데이터 조회를 할 수 있으면 괜찮지만, 그 이상으로 늦어지면 사용자 경험이 매우 떨어진다고 생각하기 때문입니다. 실시간성이 매우 중요하다면 interval을 최소 1분으로 설정할 수 있습니다.
주의 사항
위 방법으로 연동할 경우 주의 사항들은 다음과 같습니다.
•
CloudWatch Logs subscription filter 개수 제한
◦
CloudWatch Logs의 log group 별로 subscription filter는 2개까지만 설정할 수 있습니다.
◦
Airbridge에서는 New Relic과의 연동을 위해 이미 1개를 사용하고 있었기 때문에 위 방법으로 나머지 1개를 사용하여 이제 더 이상 남은 subscription filter 여분이 없습니다.
◦
만약 subscription filter 추가가 더 필요한 경우 새로운 방법을 생각해봐야 하는데, 당분간 그럴 일이 없을 것 같아 위 연동 방식을 유지하기로 했습니다.
•
Log format
◦
위 Athena table의 DDL을 보시면 알겠지만, S3에 남는 log의 format과 Athena table이 강결합 됩니다.
◦
Log 별로 table을 따로 만들지 않으려면 log format을 단순하고 일관되게 만드는 것이 좋습니다.
◦
위에서도 언급한 것처럼 저는 JSON log format을 추천합니다. Log format을 통일하고, log 내에는 JSON format을 사용하면 아래 장점들이 있습니다.
▪
CloudWatch Logs Insights를 활용할 수 있습니다. Athena까지 가지 않고 Logs Insights에서 데이터를 빨리 찾아볼 수 있으면 그게 더 낫습니다.
▪
같은 Log format 들에 대해서는 Athena table 하나로 관리할 수 있습니다.
•
비용
◦
위 방법은 일단 모든 log가 CloudWatch Logs에 남는 걸 전제로 하고 있습니다. CloudWatch Logs는 그 자체로도 인입, 보관 비용이 상당히 발생합니다. 그래서 많은 volume의 log를 처리하기엔 적합하지 않습니다.
◦
Log들이 Firehose를 거쳐 S3에 저장되므로 Firehose, Lambda, S3 비용이 추가됩니다.
IaC 하기
위 연동을 매번 손으로 추가하는 것은 상당히 번거롭습니다. 이럴 때, IaC가 또다시 빛을 발합니다. IaC 대상은 크게 세 가지입니다.
1.
Kinesis Firehose 생성
2.
CloudWatch Logs subscription filter 추가
3.
Athena table DDL
여기서 Athena table DDL이 조금 생소할 수 있으니 조금 더 살펴보겠습니다.
Athena table DDL
위 Athena table DDL에서 변경이 잦은 부분은 enum 변수로 정의해둔 log group 부분입니다. 그 외 부분은 수정할 일이 거의 없습니다. log group을 추가할 때는 TBLPROPERTIES 부분을 수정해야 하는데 ALTER TABLE SET TBLPROPERTIES query로 수정할 수 있습니다. 이 글에서는 partition projection 기능을 활용했기 때문에 명시적으로 MSCK REPAIR TABLE query가 필요 없습니다. 그래서 DROP TABLE 후 다시 CREATE TABLE을 하는 것도 방법입니다.
개인적으로는 Athena query console의 사용자 경험을 별로 좋아하지 않아서 이런 작업을 할 때 매우 불편해했습니다. 그래서 Terraform을 잘 활용하면 좋겠다는 생각을 옛날부터 해왔었는데 Athena table을 terraform으로 관리하는 예시가 생각보다 잘 안 나와서 처음 작업할 때 다소 애를 먹었습니다. 그래서 다른 분들이 같은 시간 낭비하지 않으실 수 있도록 아래 예시를 공유합니다.
resource "aws_glue_catalog_table" "airbridge_api_request_logs" {
name = "airbridge_api_request_logs"
database_name = "airbridge"
table_type = "EXTERNAL_TABLE"
parameters = {
"EXTERNAL" = "TRUE"
"classification" = "csv"
"compressionType" = "none"
"typeOfData" = "file"
"projection.enabled" = "true"
"projection.log_group.type" = "enum"
"projection.log_group.values" = join(
",",
[
for log_group_name in [
# 여기 아래에 log group name 추가
"/aws/lambda/airbridge-api-production-app",
"/aws/lambda/airbridge-api-development-app",
"/aws/lambda/airbridge-dashboard-production-app",
"/aws/lambda/airbridge-dashboard-development-app",
] : replace(log_group_name, "/", ".")
]
)
"projection.sink_date.type" = "date"
"projection.sink_date.range" = "NOW-5YEARS,NOW"
"projection.sink_date.format" = "yyyy-MM-dd"
"projection.sink_date.interval" = "1"
"projection.sink_date.interval.unit" = "DAYS"
"storage.location.template" = "s3://airbridge-logs/cwlogs-to-s3/$${log_group}/success/date=$${sink_date}/"
}
partition_keys {
name = "log_group"
type = "string"
}
partition_keys {
name = "sink_date"
type = "string"
}
storage_descriptor {
location = "s3://airbridge-logs/"
input_format = "org.apache.hadoop.mapred.TextInputFormat"
output_format = "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat"
ser_de_info {
serialization_library = "org.apache.hadoop.hive.serde2.RegexSerDe"
parameters = {
"serialization.format" = "1"
"input.regex" = "(\\d+-\\d+-\\d+\\s\\d+:\\d+:\\d+,\\d+) ([^ ]*) ([^ ]*) (.*)"
}
}
columns {
name = "request_ts"
type = "string"
}
columns {
name = "log_level"
type = "string"
}
columns {
name = "class_name"
type = "string"
}
columns {
name = "payload"
type = "string"
}
}
}
SQL
복사
사실 특별한 것은 딱히 없습니다. parameters block 아래의 것들이 TBLPROPERTIES에 들어가고, partition_keys block 아래의 것들이 PARTITIONED BY에 들어간다는 것, 그리고 storage_descriptor block에 값을 어떻게 써야 하는지 정도 참고하시면 되겠습니다.
마치며
이제 만들어진 Athena table에 대해 자유롭게 query 하여 log를 조회할 수 있습니다. 아래는 그 예시입니다.
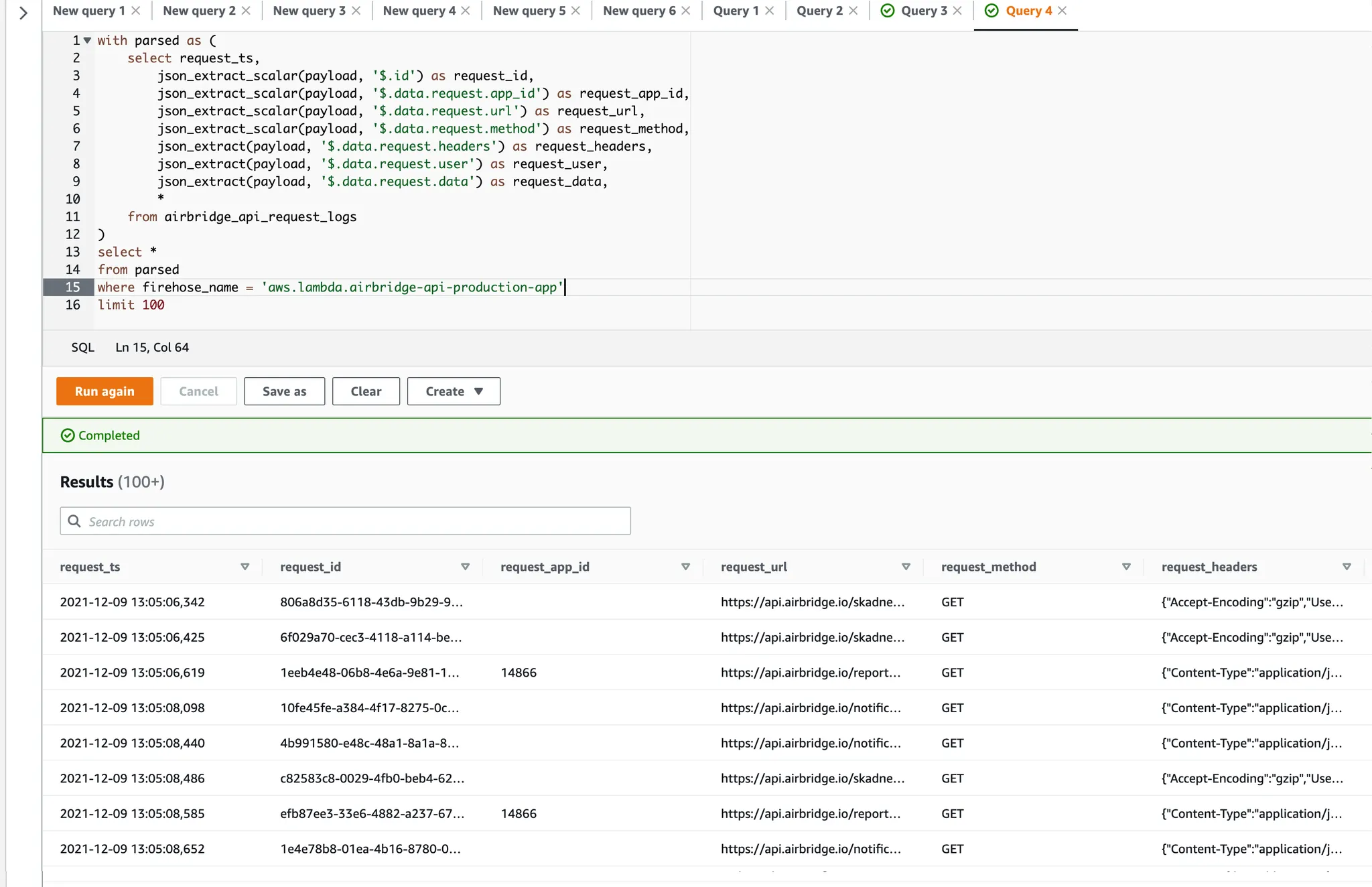
Athena가 DB의 데이터를 읽을 수 있도록 S3에 잘 sync 해두면 DB의 데이터도 join 하여 조회하기 어렵지 않습니다. 단순히 Athena에서 다른 table을 select 하는 query를 추가하고 join을 하면 되니까요.
물론 DB의 데이터를 S3에 sync 하는 것도 또 하나의 문제입니다. 저희 팀에서는 다양한 방법으로 S3에 데이터를 남기게 하고 있다 보니 큰 니즈는 없었지만, 다음에 기회가 되면 Federated Query의 JDBC connector를 활용하는 방법도 알아보겠습니다.
ᴡʀɪᴛᴇʀ
Juhong Jung @toughrogrammer
Backend Software Engineer

