

Luft, TrailDB 그리고 Ziegel
AB180 은 유저행동 분석을 위해 Luft 라는 OLAP 데이터베이스를 직접 구현해 사용하고 있습니다. 그리고 Luft 데이터 저장을 위해 지금까지 TrailDB 라는 오픈소스 스토리지 엔진을 사용하고 있었습니다. 지난 4개월 간 성능향상을 위해 직접 개발한 스토리지 엔진인 Ziegel 로 변경했는데 이 과정을 소개드립니다.
Luft 에 대해 더 자세히 알고 싶다면: https://engineering.ab180.co/stories/introducing-luft


왜?
TrailDB 는 오랫동안 우리에게 적절한 해결책이었습니다. 하지만 2019년에 개발이 중단되었고, 성능과 생산성에 몇가지 문제를 가지고 있었습니다. 이러한 문제를 해결하기 위해선, 새로운 스토리지 엔진이 필요했습니다.
1.
비효율적 멀티코어 활용: TrailDB 는 멀티코어를 효율적으로 활용하지 못하고 있었습니다. 물론 요즈음의 C/C++ 은 다양한 멀티코어 활용 기능을 언어 수준에서 지원합니다. 하지만 TrailDB 는 멀티코어 활용을 고려해 설계되지 않았고, 이 설계를 유지하면서 멀티코어를 효율적으로 활용하기는 힘들었습니다.
// finalize. this could take a while with idle CPU usage but don't panic.
// it's not freeze;
// it's because TrailDB indexing process is not parallelized yet :(
Go
복사
TrailDB 를 사용한 인덱싱 함수 주석
2.
Row 단위 데이터 저장: TrailDB 는 데이터를 row 단위로 저장합니다. 우리 워크로드는 OLAP 이기 때문에 row 단위 데이터 사용은 쿼리 성능에 부정적인 영향을 줄 수 있습니다. 또 POC 진행 결과, 대부분의 쿼리에서 column 단위 데이터 저장이 유의미한 성능개선을 준다는 것을 확인할 수 있었습니다.
3.
여러 언어를 사용한 개발: Luft 는 Go 로 작성되었고, 기존 TrailDB 는 C++ 로 작성되었기 때문에 두 언어를 사용해 개발해야 했습니다. 이로 인해 언어 컨텍스트를 변경할 때마다 프로그래머의 생산성이 감소되었고, 디버깅, 코드 재사용성 등으로 문제가 있었습니다.
작업과정
마이그레이션 작업은 다섯 단계로 나누어 진행했습니다. 각 단계에 명확한 목표와 달성조건을 정해 단계별로 완료가능하게 준비했습니다.
1.
정합성 검증을 위한 테스트 추가: 엔진 교체는 데이터베이스 전체 동작에 영향을 줍니다. 따라서 정합성 검증을 위한 테스트가 추가로 필요하였고, e2e(인덱싱, 쿼리) 테스트를 추가로 작성했습니다.
2.
엔진 교체용 인터페이스 추가: 이 때만 해도 Ziegel 전환에 대한 가시성과 신뢰가 부족했습니다. 필요하다면 롤백 하거나, 일정 부분에만 새로운 엔진을 적용해 볼 수 있게 하기 위해 교체용 인터페이스를 추가했습니다.
3.
스토리지 엔진 구현: 2022년 2월까지 개발되던 프로토타입 엔진이 이미 있는 상황이었습니다. 하지만 기능과 안정성 모두 부족한 상태였기에 추가 작업이 필요했습니다. 가능하다면 최소한의 스펙으로 Luft 에 연결해 테스트하는 것을 첫 목표로 삼았습니다.
4.
최적화 및 프로덕션 적용: 기능이 동작하더라고 성능 요구사항을 만족하지 못하면 변경하는 의미가 없습니다. 이 때 성능 목표도 설정했는데, 인덱싱 소요시간은 반으로 줄이고, 쿼리 소요시간은 1.2배 이상 늘어나지 않기를 기대했습니다.
5.
검증기간 거친 후 TrailDB 의존성 제거: 드디어 작업을 완료했습니다. 이제 적절한 검증기간을 거친 후 TrailDB 의존성을 제거합니다.
최적화 이야기
1.
측정: Go는 성능 측정을 위한 훌륭한 도구들을 제공합니다. 벤치마크 시스템이 내장되어 있으며, pprof 은 Go 에 통합되어 우수한 성능측정 및 시각화 도구를 제공합니다. 특히 웹에서 disassemble 결과를 간편하게 확인할 수 있는 경험은 놀라웠습니다.
Total: 11.55s 22.23s (flat, cum) 14.49%
. 4.22s state = pool.Get() 1b8b819: LEAQ query.pool(SB), AX combiner.go:38
. 4.22s 1b8b820: CALL sync.(*Pool).Get(SB) group_by_combiner.go:38
. . 1b8b825: LEAQ 0x48c734(IP), CX group_by_combiner.go:38
. . 1b8b82c: CMPQ CX, AX group_by_combiner.go:38
. . 1b8b82f: JNE 0x1b8c353 group_by_combiner.go:38
⋮
. . 1b8b853: MOVQ BX, 0xd0(SP) group_by_combiner.go:38
⋮
. . 1b8c353: MOVQ CX, BX group_by_combiner.go:38
. . 1b8c356: LEAQ 0x366183(IP), CX group_by_combiner.go:38
. . 1b8c35d: NOPL 0(AX) group_by_combiner.go:38
. . 1b8c360: CALL runtime.panicdottypeE(SB) group_by_combiner.go:38
. . 1b8c365: NOPL group_by_combiner.go:38
Plain Text
복사
간략화된 pprof disassemble 결과
2.
성능 측정을 위한 벤치마크 추가: 성능 개선 정도를 확인하기 위해 작업 초기에 벤치마크를 추가했습니다. 이를 통해 특정 커밋이 전체 성능에 어느 정도 영향을 주었는지 확인할 수 있습니다. 아직 아쉬운 부분은 벤치마크 데이터와 프로덕션 데이터의 괴리이며 이를 해결하기 위해 노력중입니다.
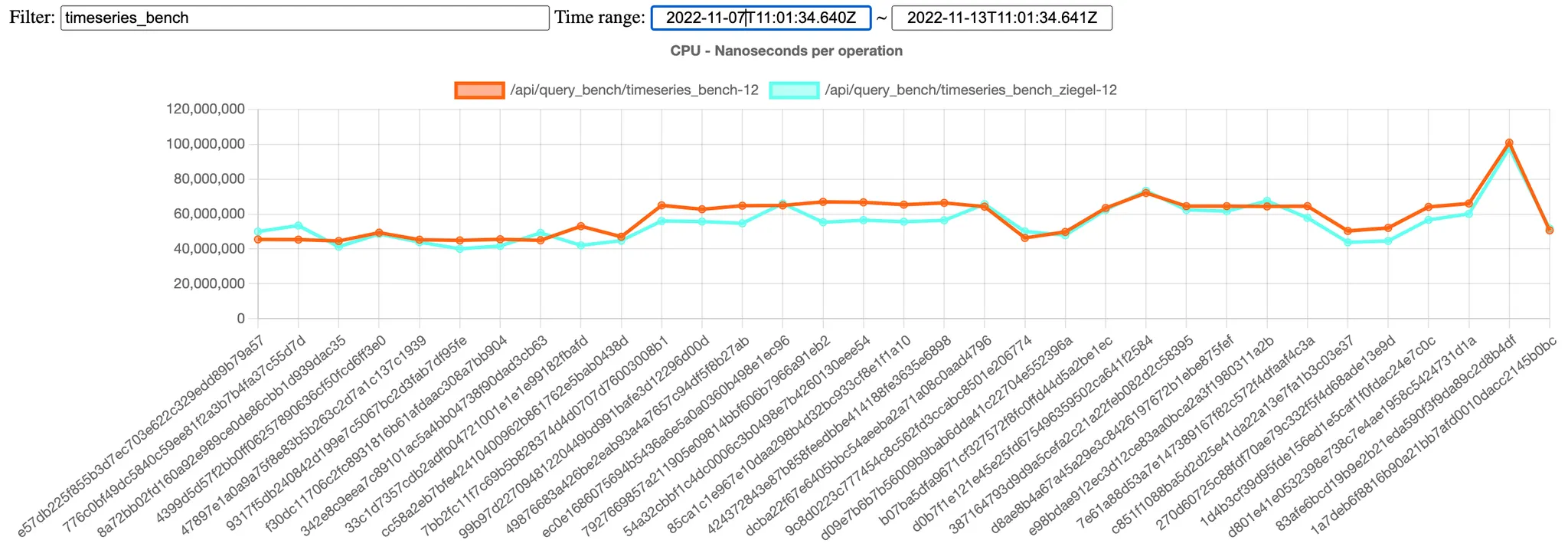
3.
기억에 남는 최적화 작업들:
a.
interface{} 로 형변환 중 메모리 할당: 프로파일 도중 형변환이 속도에 큰 영향을 준다는 것을 알게 되었습니다. 어느 정도 영향을 줄 것은 예상했지만 그 정도가 과도하여 살펴보니 형변환 시 메모리 할당이 크게 일어나는 경우를 확인하였습니다.
func convTstring(val string) (x unsafe.Pointer) {
if val == "" {
x = unsafe.Pointer(&zeroVal[0])
} else {
x = mallocgc(unsafe.Sizeof(val), stringType, true)
*(*string)(x) = val
}
return
}
Go
복사
Go 구현체에 있는 형변환 코드 일부
b.
sync.Pool 을 이용한 메모리 관리: 쿼리 중 과도하게 많은 메모리를 할당/해제하고 있었습니다. 이는 메모리 할당/해제 비용 뿐만 아니라 GC 에도 영향을 주었고, 이를 해결하기 위해 sync.Pool 을 사용했습니다. 이를 통해 간단히 적절한 성능의 메모리 풀을 적용할 수 있었습니다.
c.
로드밸런싱: 인덱싱 중 특정 노드에 작업이 몰려 전체 실행시간이 길어지는 경우가 있었습니다. 이를 해결하기 위해 로드밸런싱을 하였는데, 들인 노력에 비해 큰 실행시간 감소 효과를 보았습니다. 로드밸런싱 과정의 일부가 Snowflake 에 의존하고 있어 warehouse 크기를 늘려야 했으나 전체 실행시간 감소로 얻는 이득이 크다고 판단중입니다.
힘들었던 일
1.
unsafe 와 함께하면 Go 도 안전하지 않아!: 인덱싱 중 알 수 없는 이유로 인덱싱 결과 데이터의 일부 byte 에 이상한 값이 기록되어 있었습니다. 오랜 기간의 디버깅과 코드 리딩을 통해 확인할 수 있었던 원인은 unsafe 패키지의 잘못된 사용이었습니다. 우리는 성능향상을 위해 일부 기능에 unsafe 패키지를 사용했는데 이에 대한 잘못된 호출이 찾기 힘든 버그를 만들어냈습니다. 현재는 unsafe 패키지를 좀 더 보수적으로 사용중입니다.
// ~6x faster than ByteOrder.PutUint32
func PutUint64(data []byte, val uint64) {
data64 := *(*[]uint64)(unsafe.Pointer(&data))
data64[0] = val
}
Go
복사
unsafe 가 사용된 코드 중 일부
2.
메모리 관리의 어려움: Go 의 가비지 컬렉터는 훌륭하지만, 고성능을 원할 경우 메모리 관리를 직접 할 필요가 있습니다. 하지만 이미 가비지 컬렉터에 의존하여 작성된 코드들에서 메모리 관리를 직접 하도록 패러다임을 변경하는 것은 쉽지 않은 작업이었습니다.
type Writer struct {
c chan []byte
}
func (w *Writer) Write(data []byte) {
w.c <- data
}
Go
복사
위 코드에서 data 에 할당된 메모리 해제 시점을 특정할 수 있을까요?
3.
sync.Pool: 훌륭한 구현체이지만 우리는 너무 자주, 또 많이 메모리를 할당/해제하기 때문에 더 직접적인 메모리 관리 방법이 필요했습니다.
결과
프로덕션 환경에서 인덱싱 속도가 1.7배 가량 빨라졌고, 쿼리는 거의 비슷한 성능을 유지하고 있습니다. 아직 TrailDB 호환 인터페이스를 유지기 위해 비효율적으로 동작하는 부분이 있음에도 불구하고 이 정도 성능개선이 있다는 것은 고무적인 결과입니다.
앞으로 해야 할 일
1.
TrailDB 호환 인터페이스를 제거: 이 작업을 통해 불필요한 메모리 할당을 줄이고, Go 에 특화된 최적화 기법을 적용하여 추가적인 성능 개선을 할 수 있을 것으로 기대합니다.
2.
매우 빠른 오토스케일 지원: Luft 는 OLAP 성 워크로드를 가지기 때문에 부하가 일정하지 않습니다. 하지만 아직 Luft 의 스케일링이 충분히 빠르지 않아 실제 필요한 것보다 많은 노드를 준비해두고 있습니다. 오토스케일 속도를 늘린다면 지금보다 적은 노드로 같은 결과를 얻을 수 있을 것입니다.
3.
실시간으로 데이터 인덱싱: 현재 Luft 는 배치작업으로 인덱싱을 하고 있습니다. 그렇기 때문에 배치 주기만큼 기다려야함 데이터를 확인할 수 있습니다. 실시간 인덱싱을 지원하는 노드를 추가한다면 사용자가 기다리는 시간을 줄일 수 있을 것입니다.
4.
더 효율적인 메모리 관리: sync.Pool 은 효율적인 pool 구현체이지만 우리 데이터셋에 대해 원하는 만큼 효과적으로 동작하지 않습니다. Luft 의 쿼리는 매우 작은 메모리를 연속해 할당/해제 하는 경우가 많은데 이 상황에 특화된 메모리 관리방법을 적용할 예정입니다.
5.
컬럼 데이터 분할 다운로드: 스토리지 엔진은 이미 컬럼 단위로 데이터를 저장하고 처리하지만, Luft 는 아직 모든 컬럼을 함께 관리하고 있습니다. 이를 개선하려 하며 이는 매우 빠른 오토스케일의 사전작업입니다.
6.
유저레벨 필터: 어떤 쿼리는 이벤트 단위가 아니라 유저 단위로도 필터링할 수 있습니다. 이럴 경우 이벤트 단위 순회 자체를 하지 않게 되므로 큰 성능개선 효과를 얻을 수 있습니다.
7.
벤치마크 데이터 개선: 의미있는 수준으로 벤치마크 데이터를 키웁니다. 현재는 5분 분량의 데이터를 사용하고 있는데, 프로덕션에서는 1~3개월 데이터를 쿼리하므로 괴리가 과도하게 큽니다. 이를 해결하기 위해 벤치마크 데이터를 의미있는 수준까지 키웁니다.
마치며
스토리지 엔진를 교체하는 작업은 거의 완료되었고, 늦어도 올 해 내에는 TrailDB 의존성을 완전히 제거할 수 있을 것으로 기대합니다. 또 작업 과정에서 앞으로 해야 할 흥미로운 일들을 많이 구체화하게 되었네요. 머지 않은 미래에 또다른 흥미로운 이야기로 다시 돌아오겠습니다.
ᴡʀɪᴛᴇʀ
Jaewan Park @hueypark
Backend Engineer @AB180

